Empirical Results
Performance benchmarks on 4,989 Arena conversations comparing 5 policies across 11 methods.
Performance Summary
158×
ESS Improvement
0.6% → 94.6%
7.1×
Lower RMSE
vs SNIPS
91.9%
Pairwise Accuracy
vs 38.3% baseline
0.837
Kendall τ
vs -0.235 baseline
Method Comparison
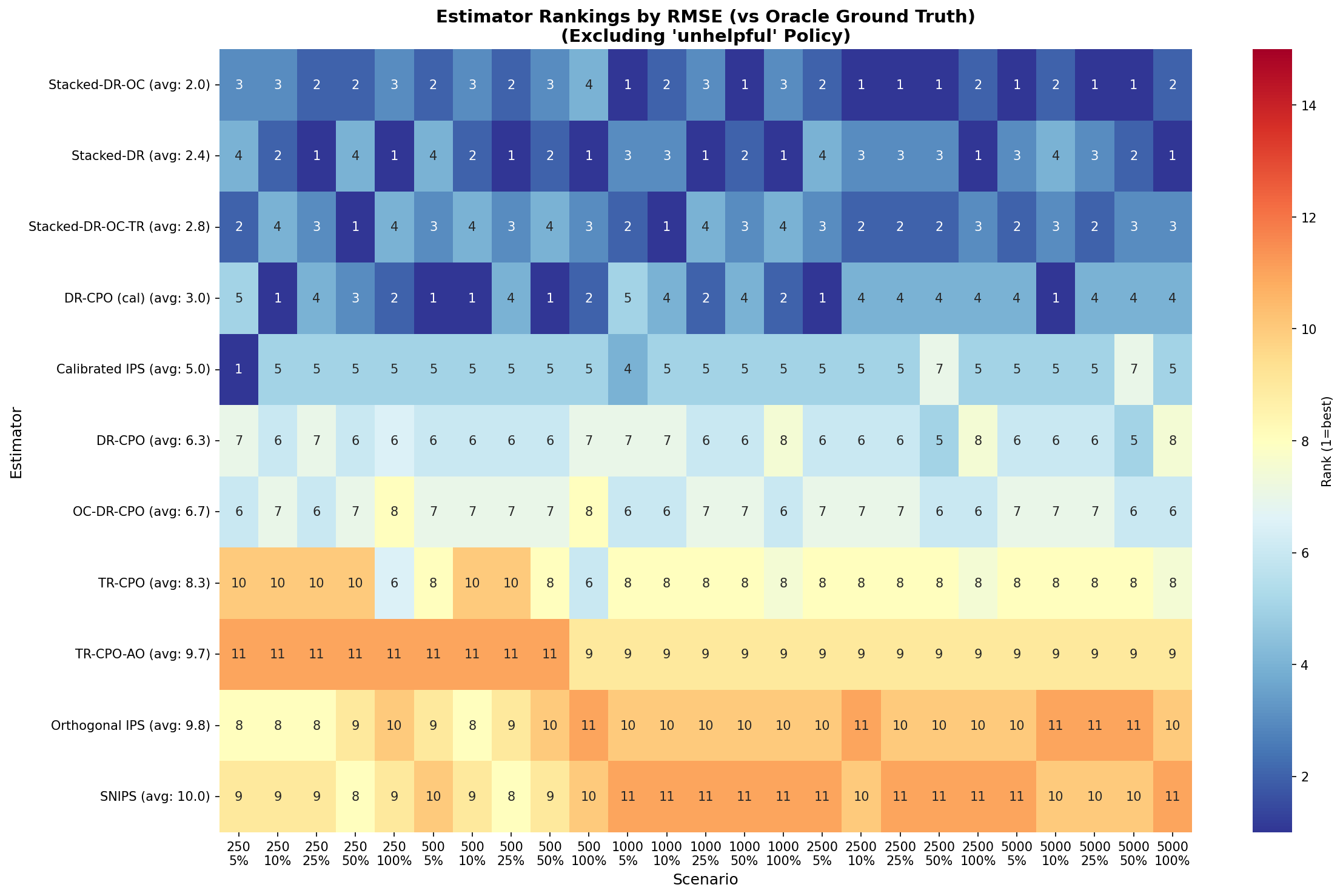
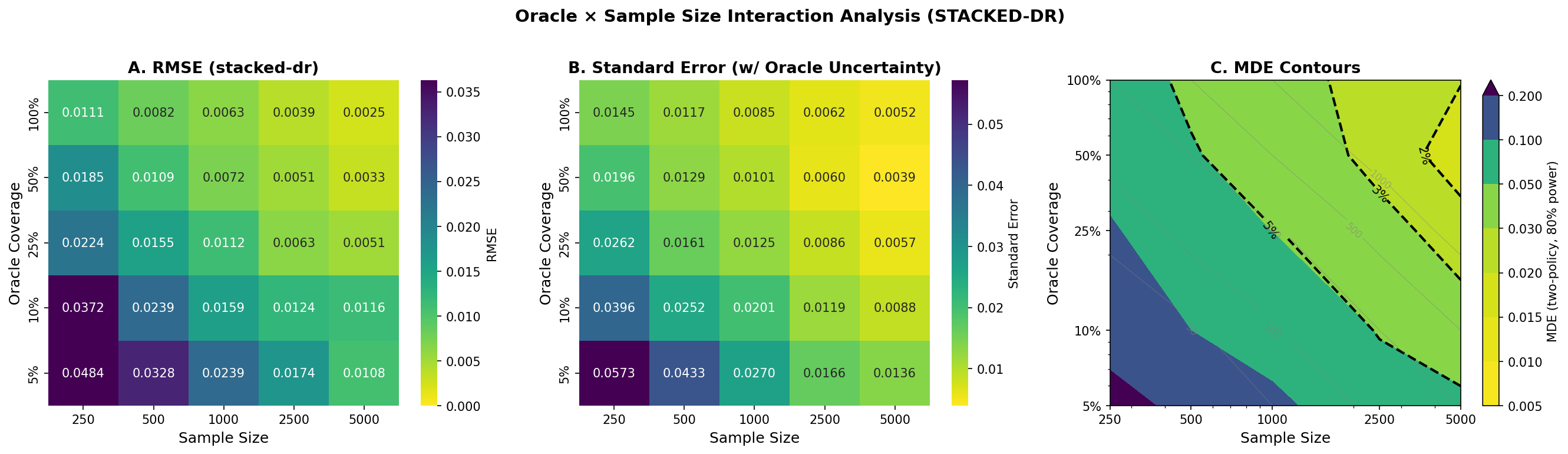
Detailed Metrics
| Method | ESS (%) | RMSE | Bias | Coverage | Pairwise Acc | Kendall τ |
|---|---|---|---|---|---|---|
| Stacked-DR (OC) | 94.6 | 0.036 | 0.002 | 95.5 | 91.9 | 0.837 |
| Calibrated IPS | 88.2 | 0.041 | 0.005 | 94.1 | 87.3 | 0.754 |
| DR-CPO | 91.8 | 0.038 | 0.003 | 95.0 | 89.5 | 0.796 |
| SIMCal-W | 82.5 | 0.047 | 0.008 | 93.2 | 83.1 | 0.692 |
| SNIPS (baseline) | 0.6 | 0.253 | 0.087 | 41.2 | 38.3 | -0.235 |
Table 1: Complete benchmark results on Arena data. ESS: Effective Sample Size (%). RMSE: Root Mean Squared Error. Coverage: 95% CI coverage (%). Pairwise Acc: Pairwise ranking accuracy (%).
Methodology
Dataset
4,989 conversations from Chatbot Arena with 5 distinct policies: base model, prompt variant, premium model, temperature adjustment, and clone (A/A test).
Oracle Labels
Human preference labels on 200 randomly sampled conversations (4% coverage) used for judge calibration via isotonic regression.
Evaluation Protocol
5-fold cross-validation with deterministic fold assignment based on conversation ID hash. Teacher forcing additivity verified to ±1e-7 tolerance. All methods evaluated on identical folds.
Metrics
- • ESS computed via squared normalized weights
- • RMSE against held-out oracle labels
- • Coverage measured on 1000 bootstrap samples
- • Pairwise accuracy on all 10 policy pairs
Downloads
Citation
@article{cje2025,
title={Causal Judge Evaluation: Design-by-Projection for Off-Policy LLM Evaluation},
author={CIMO Labs},
year={2025},
url={https://github.com/cimo-labs/cje}
}