CJE in Action
You understand why your metrics lie. Now see how simple the fix is.
Run it yourself, no installation required.
Open in Colab →CJE does three things. Each takes one code block.
1. Calibration
Your cheap judge scores (S) don't match expensive oracle outcomes (Y). CJE learns the S→Y mapping from a small labeled sample, then applies it everywhere.
from cje import analyze_dataset
# Your evaluation data - one list per policy variant
results = analyze_dataset(
fresh_draws_data={
"prompt_v1": [
{"prompt_id": "1", "judge_score": 0.85, "oracle_label": 0.9},
{"prompt_id": "2", "judge_score": 0.72, "oracle_label": 0.7},
{"prompt_id": "3", "judge_score": 0.68}, # oracle_label optional (5-25% needed)
],
"prompt_v2": [
{"prompt_id": "1", "judge_score": 0.78, "oracle_label": 0.82},
{"prompt_id": "2", "judge_score": 0.81, "oracle_label": 0.79},
{"prompt_id": "3", "judge_score": 0.75},
],
}
)
# Or load from files:
# results = analyze_dataset(fresh_draws_dir="responses/")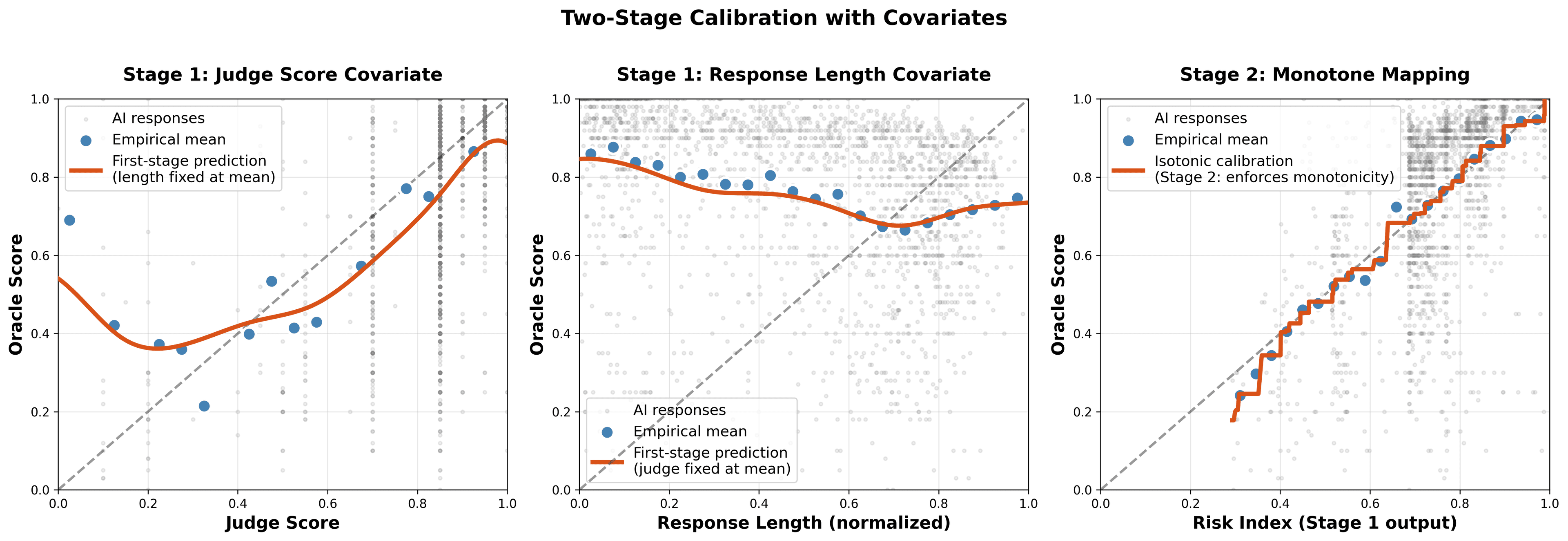
Two-stage calibration: learn flexible S→Y mapping, then ensure monotonicity.
That's it. CJE auto-detects which samples have oracle labels, fits isotonic regression for reward calibration, and returns calibrated estimates. Notice that oracle_label is optional. You only need it for 5-25% of samples.
2. Uncertainty Quantification
Raw judge scores give you a number with no error bars. CJE gives you honest confidence intervals that include both sampling variance and calibration uncertainty.
# Visualize with confidence intervals
results.plot_estimates(
policy_labels={
"prompt_v1": "Conversational tone",
"prompt_v2": "Bullet points only",
}
)
# Compare two policies with p-value
comparison = results.compare_policies(0, 1)
print(f"Difference: {comparison['difference']:.3f}, p={comparison['p_value']:.3f}")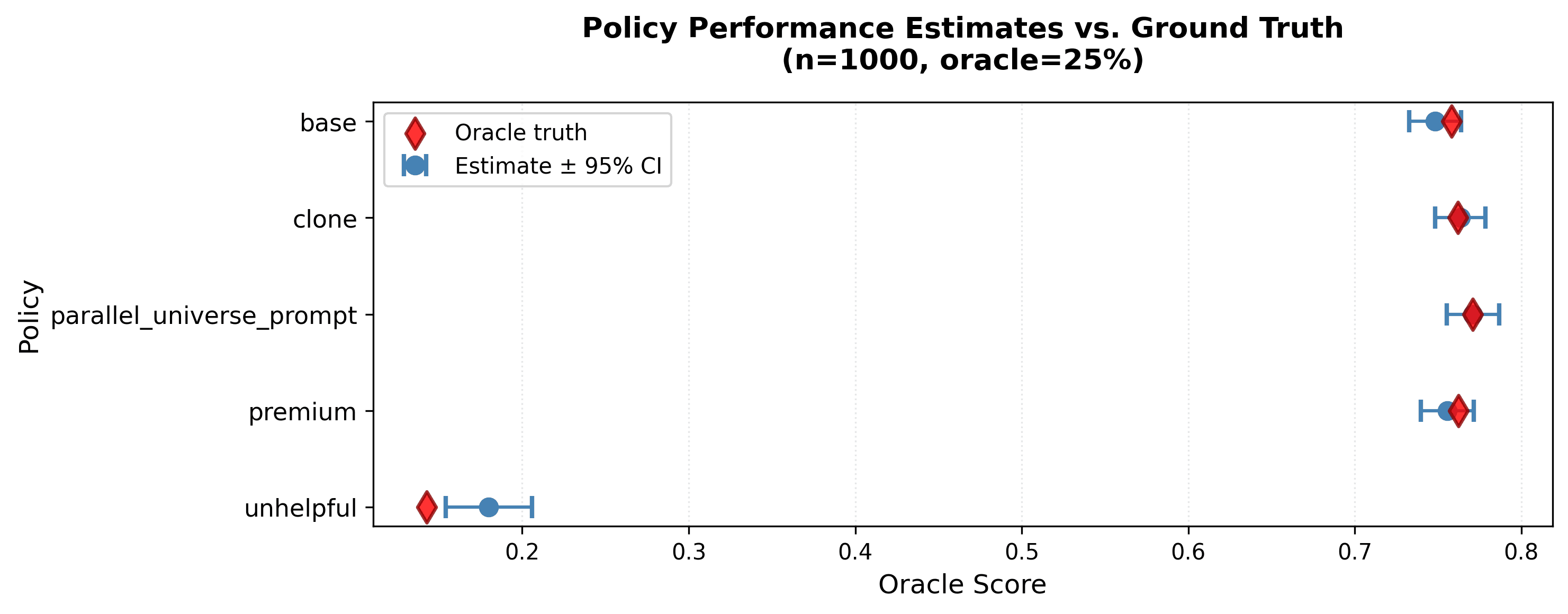
Compare prompt variants. Find the best one. Trust the error bars.
These CIs are valid when your data meets CJE's assumptions (monotone S→Y relationship, representative oracle sample). Check the assumptions →
3. Transportability Auditing
Calibration drifts. User behavior changes, models get updated, prompts evolve. CJE checks if your calibration still holds. Run it weekly with a small probe.
from cje.diagnostics import audit_transportability, plot_transport_comparison
# Weekly check: does calibration still hold?
audits = {
"Week 1": audit_transportability(results.calibrator, week1_data),
"Week 2": audit_transportability(results.calibrator, week2_data),
"Week 3": audit_transportability(results.calibrator, week3_data),
}
for name, audit in audits.items():
print(audit.summary()) # PASS or FAIL
# Visualize drift over time
plot_transport_comparison(audits, title="Weekly Calibration Check")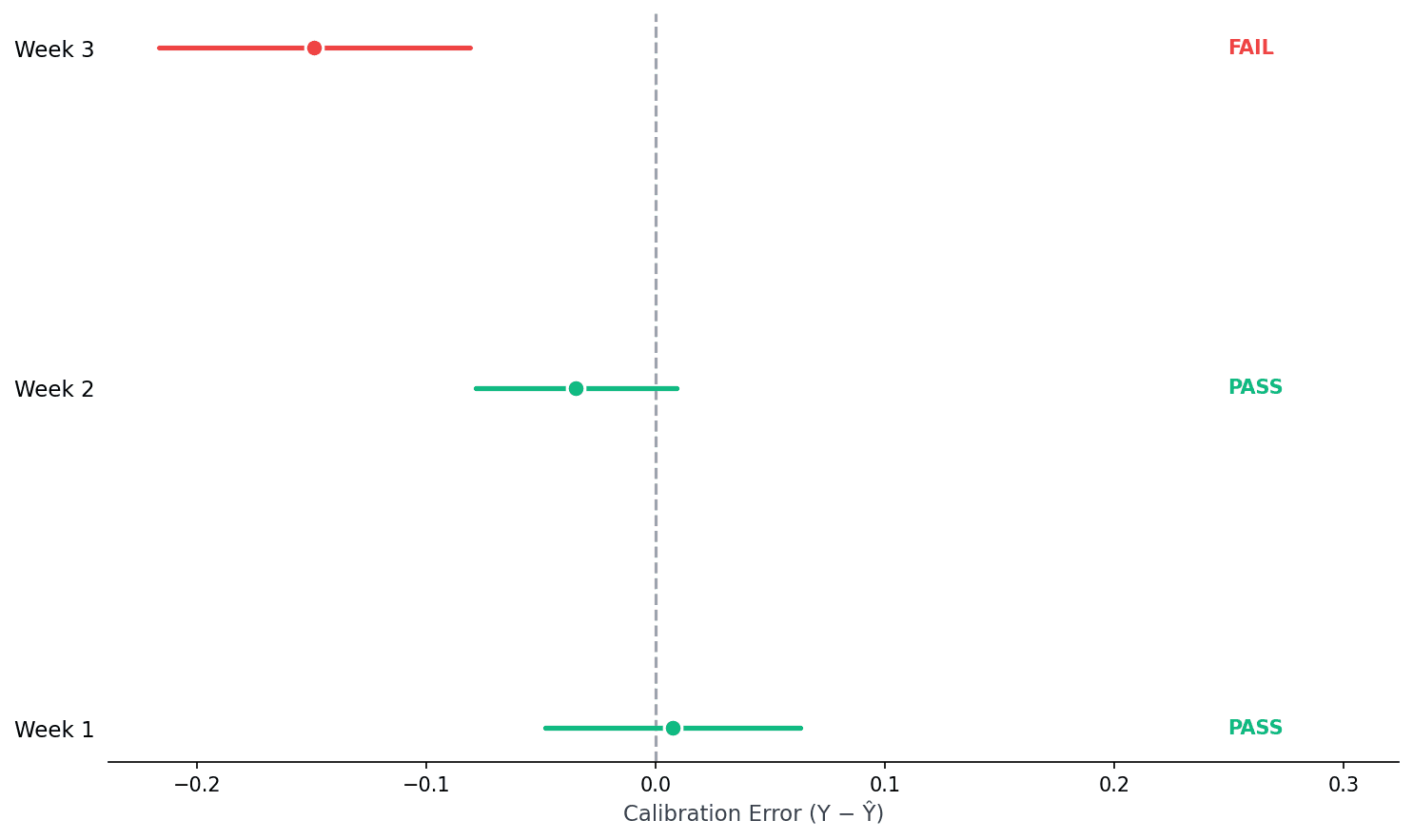
PASS = calibration still valid, trust the estimates.
FAIL = calibration has drifted, time to recalibrate.
When calibration fails
Week 3 shows systematic bias. The judge overestimates quality. This could mean user expectations shifted, the model changed, or adversarial patterns emerged. CJE catches this before you ship decisions based on stale calibration.
Bonus: Debugging Failures
When calibration fails, you need to know why. CJE lets you inspect which samples the judge gets most wrong. Find the adversarial patterns, sycophantic responses, or edge cases fooling your evaluator.

Large negative residuals = judge overestimated quality. Inspect these first.
from cje.diagnostics import compute_residuals
# Find samples where judge overestimates quality (sorted by worst first)
samples = compute_residuals(results.calibrator, probe_data)
# Inspect the worst offenders
for s in samples[:3]:
print(f"Residual: {s['residual']:.2f}")
print(f" Judge: {s['judge_score']:.2f} → Calibrated: {s['calibrated']:.2f}")
print(f" Oracle: {s['oracle_label']:.2f}")
print(f" Prompt: {s['prompt'][:80]}...")
print(f" Response: {s['response'][:80]}...")
print()Negative residuals mean the judge scored it high but the oracle scored it low. These are your failure modes: responses that look good but aren't. Fix these patterns, retrain, and your calibration improves.
That's It
Calibration
S → Y mapping
Uncertainty
Honest CIs
Transportability
PASS / FAIL
Three things. Three code blocks. That's CJE.
Run Locally
pip install cje-eval git clone https://github.com/cimo-labs/cje.git cd cje/examples jupyter notebook cje_core_demo.ipynb
Go Deeper
Benchmark Paper
Canonical empirical results on 5k Arena prompts
Assumptions
When does CJE work?
Data Format
Full docs on GitHub
Full Tutorial
Interactive Colab notebook
Try it now
Open in Colab →