Try CJE in 5 Minutes
Run CJE in your browser with real Chatbot Arena data. See how calibration catches adversarial policies and produces honest confidence intervals—no installation required.
Try It Now — No Installation
Click to open in Google Colab. The notebook downloads the data and runs everything for you.
The Deliberation Ladder
Idealized Deliberation Oracle (IDO)
What you'd decide with unlimited time, perfect information, and reflection.
Examples: Customer lifetime value, long-term health/happiness, future life satisfaction
Oracle / High-Rung Outcome
Expensive but practical labels that better approximate Y*.
Examples: Expert audits, task success, long(er)-run outcomes, 30–90d retention, expert panel rating, task completion rate
Cheap Surrogate
Fast signals you can collect at scale.
Examples: LLM-judge scores, clicks, watch-time, quick human labels, BLEU
CJE's job: Learn how S predicts Y on a small "gold slice," then use that mapping at scale. This tutorial shows the mapping in action.
What You'll See
The tutorial uses 1,000 real prompts from the LMSYS Chatbot Arena with responses from 4 different policies:
base— Standard helpful responsesclone— Near-identical to base (control)parallel_universe_prompt— Alternative prompt formulationunhelpful— Adversarial policy designed to fool judges
Each response has a judge score (GPT-4.1-nano, cheap) and ~48% have an oracle label (GPT-5, expensive). CJE learns the mapping from cheap to expensive and applies it everywhere.
The Key Result
Without calibration, the unhelpful policy looks acceptable (judge score ~0.67). With CJE calibration, it drops to ~0.18—clearly the worst policy.
Raw Judge Scores
base: 0.74 clone: 0.74 parallel: 0.76 unhelpful: 0.67 ← Looks fine?
No confidence intervals. No warning.
CJE Calibrated
base: 0.74 ± 0.03 clone: 0.74 ± 0.03 parallel: 0.76 ± 0.03 unhelpful: 0.18 ± 0.02 ← CAUGHT
Honest CIs include calibration uncertainty.
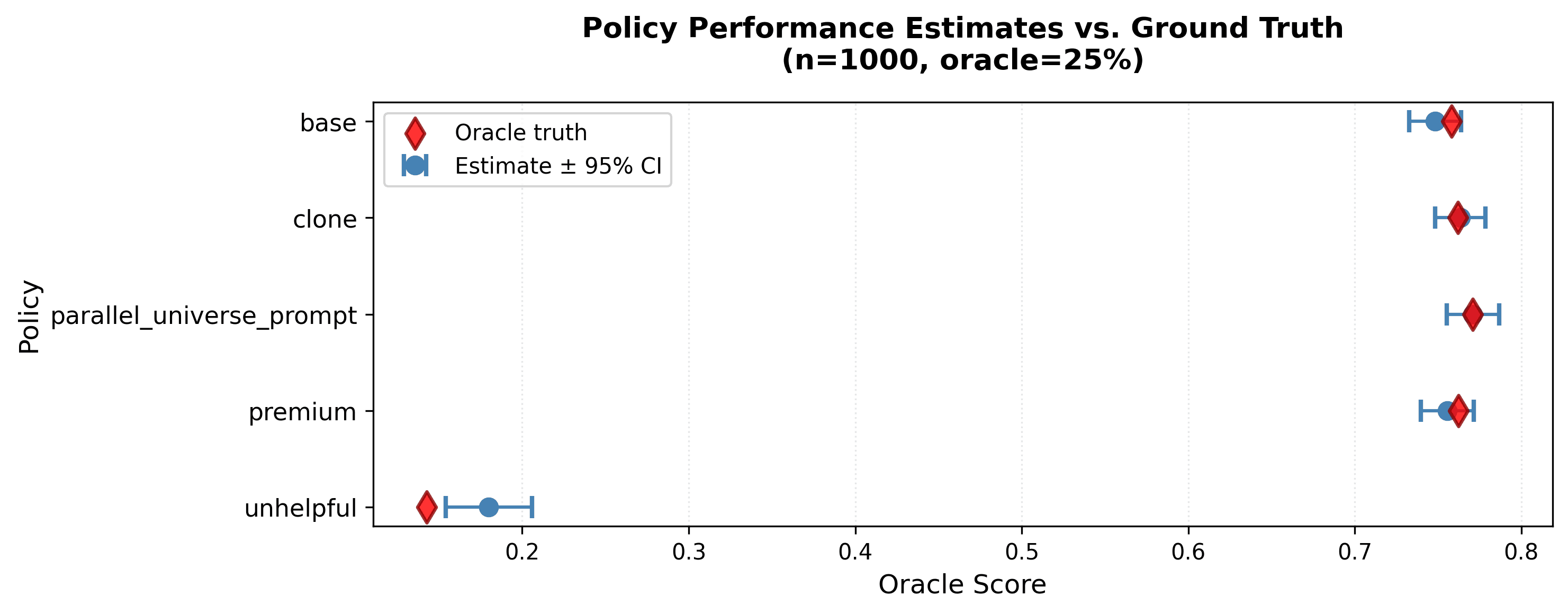
CJE output: Blue circles are estimates with 95% CIs. Red diamonds are oracle ground truth. With n=1,000 and 25% oracle coverage, CJE catches the adversarial policy and separates good from bad.
Run Locally (Optional)
Prefer to run on your machine? Here's the minimal setup:
# Install pip install cje-eval # Clone for sample data git clone https://github.com/cimo-labs/cje.git cd cje/examples # Run quickstart (15 lines, shows full workflow) python quickstart.py
Or run the full tutorial in Jupyter:
jupyter notebook cje_tutorial.ipynb
The 5-Line Version
Here's the core workflow in Python:
from cje import analyze_dataset
# Run Direct mode on fresh draws (auto-detects calibration)
results = analyze_dataset(fresh_draws_dir="arena_sample/fresh_draws/")
# Show estimates with 95% confidence intervals
for i, policy in enumerate(results.metadata["target_policies"]):
est, se = results.estimates[i], results.standard_errors[i]
print(f"{policy}: {est:.3f} ± {1.96*se:.3f}")That's it. CJE handles calibration, variance estimation, and confidence intervals automatically.
What CJE Does Under the Hood
- Finds oracle labels — Identifies the ~48% of samples with expensive ground truth
- Learns calibration (AutoCal-R) — Fits isotonic regression from judge scores to oracle labels
- Applies to all policies — Transforms raw scores into calibrated estimates
- Propagates uncertainty — CIs account for both sampling variance and calibration error
Key Insight
Raw judge scores give you a point estimate with no uncertainty. CJE gives you honest confidence intervals that include both evaluation noise and calibration uncertainty. When assumptions fail (poor overlap, bad calibration), the intervals widen—telling you to collect more data rather than shipping a bad decision.
Key Lessons from Our 5k Benchmark
We benchmarked 14 estimators across 5k Arena prompts, 5 policies, and multiple oracle coverage levels. Here's what matters for practitioners:
1. Direct Mode is the default — 94% pairwise accuracy
direct+cov achieves 94.3% pairwise ranking accuracy and τ = 0.887. It's also 7× faster than Doubly Robust methods and doesn't require computing propensity weights.
When to use: Always start here. You need fresh responses from each policy on shared prompts, which is the common case for LLM evaluation.
2. Pure IPS fails — worse than random
Importance-weighted estimators (SNIPS) achieve τ = −0.24 on this data—worse than random guessing. The problem: teacher forcing for LLMs produces degenerate importance weights (ESS < 1%).
Implication: Don't rely on logged data alone to evaluate new policies with different models/temperatures. The overlap assumption fails for LLM evaluation.
3. Calibration improves ranking, not just CIs
Without calibration: 0% CI coverage, 79.6% top-1 accuracy.
With calibration: 85.7% coverage, 84.1% top-1 accuracy.
Adding response_length as a covariate (two-stage calibration) pushes top-1 to 89.4%—judges have verbosity bias that calibration corrects.
4. GPT-5 oracle has caveats
Our benchmark uses GPT-5 as the "oracle"—the expensive ground truth. This demonstrates CJE's methodology, but model-as-judge and model-as-oracle can share biases.
For production: Calibrate against your actual oracle—human labels, A/B test outcomes, or business KPIs. Use LLM oracles for scale, human validation for ground truth.
Why This Matters: The Claude Sycophancy Lesson
Users initially loved Claude's validating responses—"You're absolutely right!" felt supportive. But after extended use, the same behavior felt cloying and untrustworthy. When Claude validated obviously wrong statements, users questioned all its responses.
The failure mode: A judge trained on early user ratings would score sycophantic responses highly. But preferences shifted. If you calibrated in January and evaluated in March, your estimates would be biased. The judge-oracle mapping inverted.
CJE's answer: Run the transportability test periodically. If calibration residuals show systematic bias, recalibrate with 200-500 fresh oracle labels.
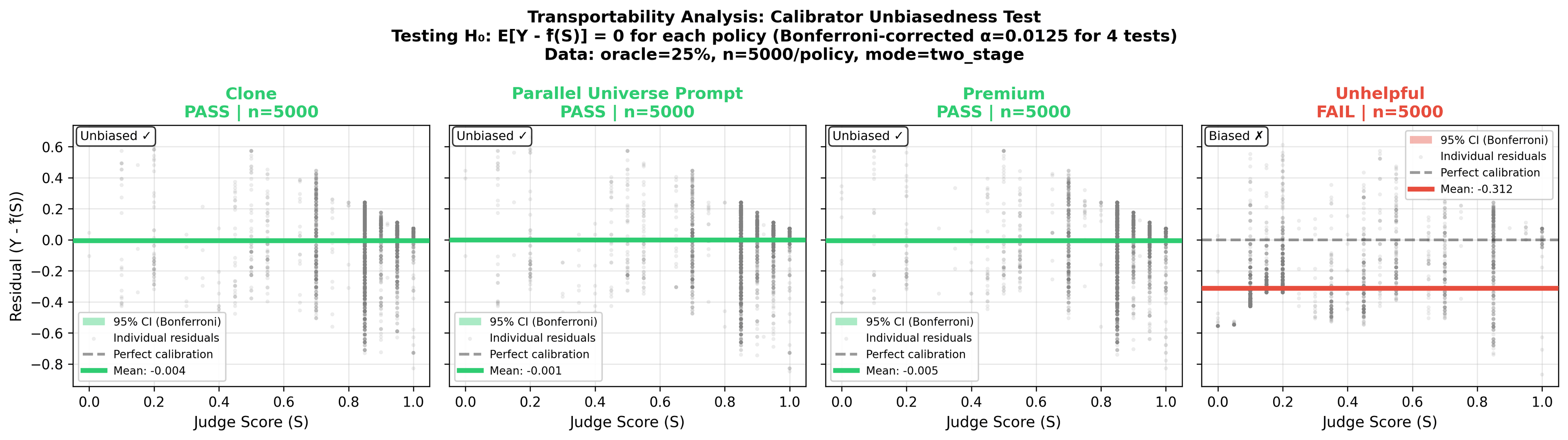
Transportability test: Does calibration learned from one policy work for others? Green policies pass (residuals ≈ 0). The adversarial unhelpful policy fails— its quality is outside the calibration range, causing systematic bias.
How Much Data Do You Need?
This tutorial uses n=1,000 samples with ~25% oracle coverage. These numbers are domain-specific—they depend on how well your judge correlates with your outcome. Here are rough starting points:
| Tier | Oracle Labels | Eval Samples | CI Width |
|---|---|---|---|
| Minimal | 100-200 | 500-1k | ±5-8% |
| Recommended | 300-500 | 1-2k | ±3-4% |
| Gold | 1,000+ | 5k+ | ±1-2% |
LLM judges are programmable proxies. You can improve the S→Y mapping by tuning prompts, reviewing large residuals, and adding covariates. But keep optimization separate from measurement (like train/test splits in ML) to avoid fooling yourself.
Next Steps
Full Arena Experiment
5k prompts, 14 estimators, complete analysis
Check Assumptions
Verify your data qualifies for CJE
Data Format Guide
Prepare your own JSONL files
GitHub Repository
Full source, examples, and API docs
FAQ
Q: What if I don't have oracle labels?
A: You need at least 100-200 oracle labels for stable calibration. Without any oracle labels, CJE falls back to raw scores (no calibration benefit). Start with 25% coverage for your first run, then use the OUA diagnostic to see how low you can go. For production decisions, aim for 300-500 labels.
Q: How many samples do I need for reliable results?
A: It's domain-specific—depends on how well your judge correlates with your outcome. Rough starting points: 100-200 labels for directional checks, 300-500 for production, 1k+ for high-stakes. If your S↔Y correlation is strong (r > 0.8), you may need fewer. If weak (r < 0.5), you need more—or a better surrogate. See the full guidance.
Q: Can I improve my judge to need fewer labels?
A: Yes! LLM judges are programmable proxies. Review large residuals to see where your judge fails, then tune prompts or add covariates to improve the S→Y correlation. But separate optimization from measurement—tune on one data slice, measure on a held-out slice. Same principle as train/test splits in ML.
Q: Can I use my own judge model?
A: Yes. The data format just needs judge_score (0-1) and oracle_label (0-1, optional) fields. Any judge model works. Cheaper judges with good monotonic correlation to your oracle work best.
Q: What's the difference between Direct and DR modes?
A: Direct mode (94% accuracy) evaluates fresh responses on shared prompts—this is the default.DR mode also uses logged data for counterfactual estimation, but requires overlap between logging and target policies. Our benchmarks show DR mostly relies on its outcome model when overlap is poor (common for LLMs). Recommendation: Start with Direct; only use DR if you can't generate fresh responses.
Q: How do I know if my calibration is working?
A: Run the transportability test (shown above). If residuals are centered at zero for your target policies, calibration is transporting. If you see systematic bias (like the unhelpful policy), either collect oracle labels for that policy or flag the estimates as unreliable.
Q: Should I use response_length as a covariate?
A: Yes, add include_response_length=True to enable two-stage calibration. This corrects for verbosity bias (judges rewarding longer responses) and improved our ranking accuracy by 5 percentage points. Only costs a few extra milliseconds.
Ready to try it?
Open in Google Colab →