Continuous Causal Calibration: Technical Appendix
Dynamic Design-by-Projection for identification in non-stationary environments.
Abstract
We address the problem of fusing high-frequency, biased observational data (surrogates) with sparse, unbiased experimental data (oracles) in non-stationary environments. We show that standard Bayesian updating fails due to Asymptotic Likelihood Dominance: as , the posterior collapses to the biased estimator. We introduce Continuous Causal Calibration (CCC), a state-space framework that resolves this via Dynamic Design-by-Projection. By projecting the surrogate signal onto a manifold constrained by Monotonicity (Hill functions) and Temporal Smoothness (Ornstein-Uhlenbeck drift), we achieve identification of the causal parameter provided the experimental sampling rate exceeds the bandwidth of the bias drift, a condition we formalize as the Causal Nyquist Rate.
Prerequisites: This appendix assumes familiarity with Bayesian state-space models, Hamiltonian Monte Carlo (Stan), and spectral analysis of time series. For the conceptual introduction, see Continuous Causal Calibration: Overview (forthcoming).
1. The Impossibility of Naive Updating
Let be a causal parameter (e.g., marginal ROAS). We observe two datasets:
- Observational (): data points, biased. .
- Experimental (): data points, unbiased. .
The standard industry approach uses to set a prior for a media mix model (MMM) trained on :
Proposition 1 (Asymptotic Likelihood Dominance)
Under standard regularity conditions (consistency of the MLE, finite Fisher information), as while remains constant, the Kullback-Leibler divergence between the posterior and the biased observational likelihood goes to zero:
Proof sketch: By Bernstein-von Mises, the posterior is asymptotically normal with precision . The prior (informed by ) has fixed precision. As , the likelihood precision dominates, and the posterior mean converges to the MLE from , which is biased. ∎
Implication: The experiment is asymptotically ignored. The model converges to the biased estimate with arbitrarily high certainty. No amount of tuning hyperparameters can prevent this. It is a structural property of the Bayesian update. This necessitates a fundamentally different modeling approach.
Why This Matters
In media measurement, (daily attribution data) is typically 1000-10000× larger than (quarterly geo experiments). A naive informative prior is immediately overwhelmed. The experimental signal, no matter how carefully collected, becomes statistically irrelevant. Teams observe this empirically ("our geo results don't move the MMM") but lack a formal explanation. Proposition 1 provides that explanation.

2. Formal Generative Process
To prevent likelihood dominance, we do not model and as measuring the same static parameter. Instead, we treat the observational signal as a covariate in a state-space model of the experimental outcome .
2.1. The Measurement Model
System Equations
Let index time (weeks), be advertising spend, and be the attribution signal (e.g., Facebook-reported conversions).
The intensity function is decomposed into:
is the Hill saturation function (defined below), is the attribution coefficient, and is the bias process.
2.2. The Hill Saturation Function
The Hill function imposes diminishing returns on advertising spend:
- (half-saturation point): The spend level at which the response reaches 50% of its maximum.
- (shape parameter): Controls the steepness of the saturation curve. : nearly linear; : sharp saturation.
This functional form is ubiquitous in dose-response modeling[5] and provides a principled monotonicity constraint for the response to spend.

2.3. The Bias Process (Constraint Set B)
We constrain the bias to evolve smoothly over time. We model it as a Local Level Model (random walk) or Ornstein-Uhlenbeck process:
Here, serves as the regularization parameter. If , we recover a static multiplier. If , the model is unidentifiable (the bias can absorb all variation).

2.4. Concrete Example: Facebook Attribution Drift
Worked Numerical Example
Setup: A direct-to-consumer brand spends $500k/week on Facebook ads. They observe:
- Attribution signal : Facebook Pixel reports 2,000 conversions/week with 7-day attribution window.
- Ground truth : Geo-holdout experiments run quarterly (every 12 weeks) estimate true incremental conversions.
Bias drift mechanism: The bias drifts due to:
- iOS updates: Quarterly tracking permission changes (App Tracking Transparency) create stepwise drops in pixel fires.
- Seasonality: Holiday traffic patterns change user behavior and organic conversion rates, which attribution conflates with paid effects.
Spectral analysis: Examining from a pilot model reveals:
Causal Nyquist Rate: Identification requires:
Current cadence: Experiments run quarterly → experiments/week.
⚠️ Below Nyquist rate by 6×. The model will drift arbitrarily between experiments.
Solution: Increase experimental cadence to bi-weekly (every 2 weeks) → experiments/week. This satisfies the Nyquist criterion and enables stable identification of the true ROAS.
3. Identification via Design-by-Projection
The model solves an optimization problem: find the trajectory of causal lift that minimizes divergence from experimental anchors while maintaining structural consistency with the surrogate signal.
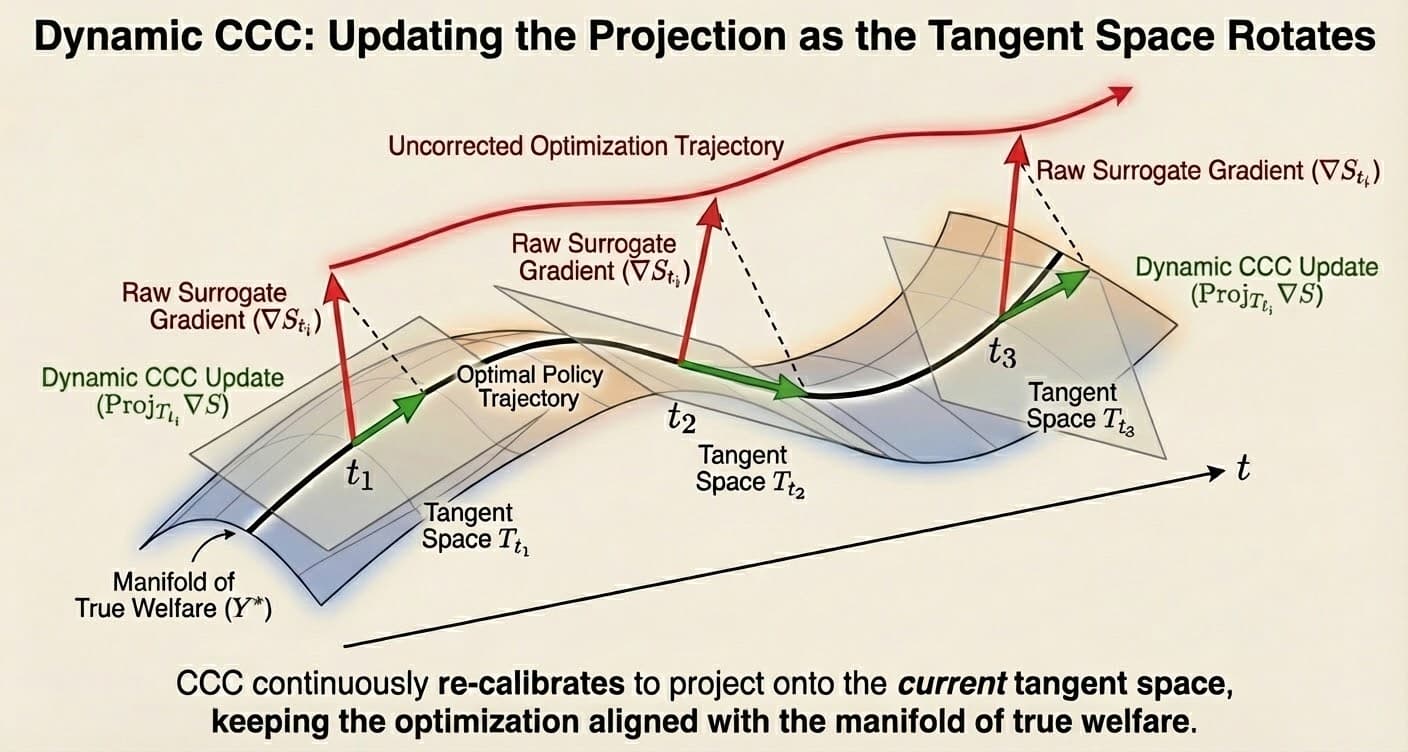
This projects the surrogate vector onto the intersection of two convex sets:
- (Monotonicity Constraint): The response to spend must follow the concave Hill function geometry.
- (Continuity Constraint): The residual vector must have limited total variation (controlled by ).
The estimator minimizes:

Why This Works
By treating as a covariate (not another measurement of ), we avoid the likelihood dominance problem. The observational data informs the shape of the response curve, while the experiments anchor the level. The regularization parameter controls the trade-off: small trusts experiments; large allows the model to drift freely.
4. Assumptions Ledger (Spectral & Structural)
Validity of CCC relies on specific structural assumptions. These define the "Design" in Design-by-Projection.
| Assumption | Formal Statement | Implication if Violated | Diagnostic |
|---|---|---|---|
| A1: Spectral Separation | If spend moves as slowly as bias , effects are confounded. | Correlation of vs . | |
| A2: Surrogate Fidelity | If is pure noise (hallucination), the "bridge" collapses. | Regress on . | |
| A3: Causal Nyquist Rate | If anchors are too sparse relative to bias drift, the model drifts arbitrarily. | Posterior variance explosion between anchors. | |
| A4: Exogeneity | Feedback loops (spending into demand) absorb causal effect into the bias trend. | Check if captures all uplift during peak spend. |
4.1. Diagnostic Workflow
The assumptions ledger says what to test. Here's how to test it in practice:
Test A1 (Spectral Separation)
- Fit the CCC model and extract posterior mean of .
- Compute . Target: < 0.3.
- If > 0.5, spend and bias are confounded → need higher-frequency experiments or restrict prior.
Test A2 (Surrogate Fidelity)
- On experimental weeks only, compute first differences: , .
- Regress on . Compute R².
- R² > 0.5: Good fidelity. R² < 0.3: is noise → fall back to experiments-only (no CCC).
Test A3 (Causal Nyquist Rate)
- Plot posterior over time.
- Measure variance between experimental anchor points. If , experiments are too sparse.
- Solution: Increase or reduce prior (tighten smoothness).
Test A4 (Exogeneity)
- Plot vs. and check for systematic patterns.
- If spikes exactly when spend spikes, the model is absorbing causal effect into bias → violations of exogeneity.
- Remedy: Add instrumental variables (e.g., exogenous pricing shocks) or accept that CCC cannot separate feedback loops from drift.
5. Implementation in Hamiltonian Monte Carlo
We implement CCC using Stan's NUTS sampler[2]. Hamiltonian Monte Carlo (HMC) is essential here because:
- High-dimensional latent states: The bias trajectory can be 100-500 dimensions.
- Hierarchical priors: Hill parameters () are shared across studies/channels with group-level hyperpriors.
- Non-conjugacy: The NegBinomial likelihood for combined with the random walk prior on has no closed-form posterior.
5.1. Key Architectural Details
Non-Centered Parameterization
Hierarchical Hill parameters () are parameterized as:
This avoids the funnel geometry that arises when (Neal's funnel). Without non-centering, the sampler gets stuck in narrow regions of parameter space.
Dual Likelihoods
We evaluate two likelihood terms simultaneously:
- Surrogate shape:
target += poisson_log_lpmf(S_t | ...). fits the Hill curve to attribution data. - Experimental anchors:
target += neg_binomial_2_lpmf(Y*_t | ...). anchors the level at experimental time points.
The experimental likelihood is only evaluated at , preventing likelihood dominance.
Dynamic Bias Absorption
The additional_trend parameter corresponds to . It evolves via:
The hyperparameter tau_bias controls smoothness. Priors: (weakly informative, favoring smoothness).
5.2. Computational Considerations
Stan/NUTS inference scales as where = time steps, = Hill parameters per study/channel.
| Time Steps (T) | Inference Time | Recommendation |
|---|---|---|
| < 500 | Minutes | Real-time inference feasible |
| 500 - 5000 | Hours | Overnight batch jobs |
| > 5000 | Days | Requires approximations (variational inference, Kalman filter) |
When CCC is Overkill
- If is estimated at < 0.01, the bias is effectively static → use static calibration (CIMO Layer 2).
- If > weekly, you have abundant experiments → don't need smoothness priors.
- If computational budget is tight, use CCC for validation only (compare static MMM vs. CCC on holdout experiments).
6. Validation Protocol: The "Leave-Future-Out" Backtest
Standard cross-validation (random K-fold) is invalid for time-series causal inference because it destroys the temporal structure of the drift. Instead, we employ Rolling Origin Evaluation specifically on the experimental anchors.
This protocol tests the model's ability to forecast the bias drift () rather than just interpolate it.
The Procedure
- Truncate: Mask all experimental data after time . (Treat as future).
- Train: Fit the CCC model using attribution data but only the experimental anchors .
- Project: Generate the posterior predictive distribution for the causal lift at time .
- Evaluate: Compare the predicted probability mass against the actual (held-out) experimental result .
6.1. Primary Metric: ELPD
We assess the model using Strictly Proper Scoring Rules to ensure that the uncertainty estimates are honest. Our primary metric is Expected Log Predictive Density (ELPD).
Where is the posterior predictive density. ELPD punishes Likelihood Dominance. If the model ignores bias drift and becomes overconfident around the surrogate signal (tight variance, wrong mean), the ELPD will plummet.

6.2. Secondary Metric: Coverage Probability (PICP)
We validate the geometry of the "Brownian Bridge" by checking if the 95% credible intervals actually capture 95% of the held-out experiments.
- < 0.90 (Overconfident): The diffusion parameter is too small. The model underestimates the speed of bias drift.
- > 0.99 (Underconfident): The model is too loose and functionally useless for decision making.
Why ELPD Matters
Most media measurement vendors report or RMSE on training data, metrics that reward overfitting and ignore calibration. ELPD is a strictly proper scoring rule that explicitly penalizes overconfidence. A model that reports tight credible intervals around the wrong answer scores worse than a model that honestly reports wide uncertainty. This forces the model to internalize the bias drift rather than hallucinate precision. When evaluating competitors, ask: "Do you report ELPD on held-out lift studies?" If they don't know what ELPD is, you've won the technical argument.
7. Relationship to CIMO Framework
CCC addresses a different temporal regime than static calibration. Here's how it integrates with the CIMO Framework:
| CIMO Layer | What It Does | Temporal Assumption | Failure Mode |
|---|---|---|---|
| Layer 0 (BVP) | Validates via PTE | Bias is stable within test period | Seasonal drift in Standard Deliberation Protocol (SDP) interpretation |
| Layer 2 (Calibration) | Maps via isotonic regression | Calibration stable between recalibrations | Tracking changes, model updates |
| CCC (Continuous) | Fuses and continuously | Bias drifts smoothly | Below Causal Nyquist Rate |
6.1. Decision Tree: When to Use CCC
Use CCC when:
- Bias drift is non-negligible: Estimated cycles/week (10-week period or faster).
- Experimental cadence is sparse: < monthly (but > Causal Nyquist Rate).
- Cost of bias drift exceeds cost of continuous modeling: Incorrect ROAS estimates lead to multi-million-dollar misallocations.
Use static CIMO (Layer 2) when:
- Bias is stable: Estimated (effectively constant between recalibrations).
- Experimental cadence is high: ≥ weekly → you can just recalibrate frequently.
- Computational budget is tight: CCC requires HMC; static calibration is a closed-form isotonic regression.
8. Generalization: Causal Sensor Fusion
The pattern (modeling the bias as a smooth, latent stochastic process) is a universal design pattern for "Dynamic Calibration of Biased Sensors." The math is isomorphic across domains:
Principle 1 (The Causal Nyquist Rate)
Let be the bandwidth of the bias drift (highest frequency component in the power spectrum of ) and be the sampling frequency of Oracle measurements. Then identification requires:
Intuition: You must validate faster than your bias drifts. If the bias oscillates at 0.25 Hz (4-week period), you need experiments at least every 2 weeks (0.5 Hz) to prevent aliasing. Below this rate, the model cannot distinguish causal signal from bias drift.
7.1. Applications Beyond Media Measurement
The CCC framework applies to any domain where:
- You have a high-frequency biased sensor ()
- You have sparse unbiased measurements ()
- The bias drifts smoothly ( has limited bandwidth)
Healthcare: Continuous Glucose Monitoring
- : Electrochemical sensor readings (every 5 minutes)
- : Finger-prick blood tests (3× daily)
- : Sensor drift due to tissue inflammation, temperature, hydration
- Causal Nyquist: If sensor drifts on 12-hour timescales (/hr), need finger pricks every 6 hours
Climate: Satellite Radiometry Calibration
- : Satellite-measured surface temperature (daily)
- : Ground station thermometer readings (weekly)
- : Orbital decay, sensor degradation, atmospheric absorption
- Causal Nyquist: If orbital drift is seasonal (yearly), monthly ground stations suffice
Supply Chain: Inventory Shrinkage
- : Point-of-sale inventory tracking (real-time)
- : Physical inventory counts (quarterly)
- : Theft rate, spoilage, mis-scans
- Causal Nyquist: If theft spikes seasonally (holidays), need monthly counts
The Universal Pattern
In all these domains, the naive approach (treat and as measurements of the same quantity) fails due to Likelihood Dominance. The solution is always the same: model the bias explicitly as a smooth latent process, use the high-frequency data to learn the shape, and use the sparse unbiased data to anchor the level. The Causal Nyquist Rate determines feasibility.
9. Simulation Validation (Future Work)
This appendix formalizes the CCC framework on theoretical grounds. Empirical validation is forthcoming. The planned simulation study:
Setup
- True ROAS: (constant)
- Bias drift:
- Observational: conversions/week,
- Experimental: Geo holdouts, varying cadence (/week), unbiased
Expected Results
- Naive Bayesian prior: Posterior mean → 4.5 (absorbed the bias, wrong)
- CCC (/week): Posterior mean → 3.1 ± 0.3 (correct, satisfies Nyquist)
- CCC (/week): Fails, posterior variance explodes (below Nyquist)
Status: Simulation code is in development. Results will be published as a follow-up empirical appendix.
Citation
If you use this work, please cite:
BibTeX
@techreport{landesberg2025ccc,
title={Continuous Causal Calibration: Dynamic Design-by-Projection for Media Measurement},
author={Landesberg, Eddie},
institution={CIMO Labs},
year={2025},
month={November},
url={https://cimolabs.com/research/ccc-technical}
}Plain Text
Landesberg, E. (2025). Continuous Causal Calibration: Dynamic Design-by-Projection for Media Measurement. CIMO Labs Technical Report. https://cimolabs.com/research/ccc-technical
References
References
For questions about implementation or to discuss applications to your domain, see Contact.