Causal Judge Evaluation: Oracle-Efficient, Statistically Valid LLM Evaluation
Authors: Eddie Landesberg, CIMO Labs
Date: November 2025
Technical Report
Production
Battle-tested, empirically validated
Abstract
Problem. Evaluating large language models (LLMs) against expensive oracle labels (user conversions, human preferences, long-term outcomes. Is prohibitively costly and slow at scale. The standard workaround is to use cheap LLM judges as proxies, but uncalibrated judges produce dangerously misleading results: preference inversion (high scores predict low value), invalid confidence intervals (0% coverage), and catastrophic off-policy estimation failures.
Solution. We introduce Causal Judge Evaluation (CJE), a framework for calibrating cheap surrogate judges (S) to expensive oracle labels (Y) using a small labeled slice, with statistically valid uncertainty quantification.
Key Result. Direct Method + Two-Stage Calibration achieves 99% pairwise ranking accuracy, 14× cost reduction vs. pure oracle labeling, and valid 95% confidence intervals.
Related Documents
Your AI metrics are lying to you.
If you've seen developers banning their AI assistant from saying "You're absolutely right!", you've witnessed a metric failure in production. What scored high on early evaluations (polite, affirming language) quickly became a symbol of untrustworthy sycophancy.
This wasn't a quirk. It was preference inversion: what scored highest on cheap surrogate metrics (S) predicted lower value on what actually mattered (developer productivity (Y). The optimization target was fundamentally misaligned with the evaluation target.

Figure 1: The Evaluation Problem. We observe outcomes under logging policy π₀ but want to estimate value under target policy π.
The Three Systematic Failures
Before introducing the CJE framework, we preview three specific failure modes that plague LLM evaluation.
Failure 1: Uncalibrated Judges → Preference Inversion
The Problem. LLM-as-judge scores (S) are treated as if they were reward values (Y) on the same scale. They aren't. Without calibration, higher S can predict lower Y.
The Solution (§3). AutoCal-R uses isotonic regression to enforce monotonicity. The Arena benchmark shows this eliminates preference inversion and improves ranking accuracy by 12%.
Failure 2: Ignoring Oracle Uncertainty → Invalid Confidence Intervals
The Evidence. Estimators without Oracle-Uncertainty-Aware (OUA) inference achieve 0% coverage. Their 95% CIs capture the true value 0% of the time.
The Solution (§4). OUA inference decomposes total variance and achieves valid 95% coverage.
Failure 3: Standard IPS → Catastrophic Failure Despite High ESS
The Evidence. IPS achieves ESS = 500+ after weight stabilization, but ranking performance is near-random: 56% pairwise accuracy vs. 50% chance baseline.
The Solution (§5). The Coverage-Limited Efficiency (CLE) bound provides a theoretical framework consistent with these results. TTC < 0.7 is a red flag: logs-only IPS will fail.
2. The Causal Judge Evaluation Framework
To fix the three failures identified above, we need a formal framework that makes explicit what calibration must do (enforce sufficiency), what uncertainty must capture (both evaluation and calibration), and when off-policy methods are reliable (coverage requirements). This section provides the statistical foundations.
2.1 Problem Formulation
Standard evaluation treats observed logs as the only reality. When a model generates responses under logging policy π₀, standard practice analyzes those responses as if they fully represent all possible policies. This ignores the parallel universes problem at the heart of causal evaluation.
Every AI evaluation asks: If we deploy policy π in production, what average value V(π) will we observe? But we can only observe outcomes under the deployed policy π₀. In causal terms, we want counterfactual outcomes: data from parallel universes where different policies were deployed.
The goal of causal evaluation is to fill in the missing data for unobserved policies using explicit assumptions and statistics.
2.2 The Ladder of Value and Three Oracles
We distinguish three quality levels:
1. S (Surrogate): Cheap, abundant, biased
- • Examples: GPT-4.1-nano scores, click-through rate, engagement time
- • Cost: $0.01 per label
- • Scale: Millions of labels
2. Y (Operational Oracle): Expensive but measurable
- • Examples: Human expert ratings, GPT-5 judgments, 90-day retention
- • Cost: $0.16 per label (16× more expensive)
- • Scale: Hundreds to thousands of labels
3. Y* (Idealized Deliberation Oracle): What you truly care about
- • Definition: Outcome under perfect deliberation with full information
- • Cost: Effectively unmeasurable (infinite deliberation)
- • Scale: Zero direct observations
2.3 Surrogacy Assumptions
To identify V(π) using surrogates, we require five key assumptions:
S1 (Prentice Sufficiency)
There exists a measurable function f: S × X → [0,1] such that:
Interpretation: Given the surrogate S and covariates X, the oracle Y is independent of the action A. The surrogate "captures all relevant information" about Y.
S2 (S-Admissibility / Transportability)
The same calibration function f transports across environments g ∈ G:
Interpretation: Calibration f learned in one environment (e.g., development cohort) transports to another (e.g., production).
S3 (Overlap / Positivity)
For off-policy evaluation:
Interpretation: Actions taken by the target policy π must have non-zero probability under the logging policy π₀.
L1 (Oracle MAR)
Let L ∈ {0,1} indicate whether an example received an oracle label Y:
Interpretation: Oracle labeling is ignorable conditional on observed surrogates and covariates.
L2 (Oracle Positivity)
Interpretation: Every region of (X, A, S) space where we'll apply the calibration function has positive probability of receiving an oracle label.
2.4 Three Regimes of Surrogacy
We organize estimation strategies by the strength of transportability assumptions:
| Regime | Assumptions | Labels needed? | Scope |
|---|---|---|---|
| 1. No surrogacy | None | Every environment | Nowhere beyond labeled context |
| 2. Local | S1 in g* | Once per environment | Policies within g* |
| 3. Global (CJE) | S1 + S2 | Once total | Policies + environments in admissible set |
2.5 Estimators: Direct, IPS, DR
Given assumptions S1-S3, L1-L2, we have three estimators for V(π):
2.5.1 Direct Method (DM)
Setup: Can generate fresh responses from π on shared prompt set X.
Method:
- Collect oracle labels Y on a random sample (X_i, A_i)
- Fit outcome model μ̂(A, X) = E[R | A, X] where R = f̂(S, X) is calibrated reward
- Evaluate: V̂_DM(π) = (1/n) Σ μ̂(π(X_i), X_i)
Pros: No overlap requirement, stable across sample sizes, highest ranking accuracy (99%)
Cons: Requires ability to generate fresh responses, vulnerable to model misspecification
2.5.2 Inverse Propensity Scoring (IPS)
Setup: Have logged data from π₀, can estimate propensities.
Method:
- Estimate propensity scores ê(a|x) = π₀(a|x)
- Compute importance weights: w_i = π(A_i | X_i) / ê(A_i | X_i)
- Evaluate: V̂_IPS(π) = (1/n) Σ w_i R_i
Pros: Unbiased under overlap (S3), doesn't require outcome model
Cons: High variance, coverage-limited (fails when target actions atypical for logging policy). Arena result: 56% pairwise accuracy despite ESS = 500+
2.5.3 Doubly Robust (DR)
Setup: Have both outcome model and propensities.
Method:
- Fit both μ̂(A,X) and ê(a|x)
- Combine:V̂_DR(π) = (1/n) Σ [μ̂(π(X_i), X_i) + w_i(R_i - μ̂(A_i, X_i))]
Pros: Unbiased if either μ̂ or ê is correct (double robustness), lower variance than pure IPS, best of both worlds when overlap is reasonable
Cons: Still requires overlap (though less sensitive than pure IPS), more complex to implement
Arena Result: DR with two-stage calibration and SIMCal-W achieves 99% pairwise accuracy (ties DM), but trails DM in low-overlap regimes.
2.6 Identification Results
Theorem 1 (Identification under S1)
If S1 holds, then for any policy π:
where f is the calibration function S1 guarantees exists.
Proof sketch: By S1, E[Y | X, A, S] = f(S, X). By iterated expectation, V(π) = E[Y | A = π(X)] = E[E[Y | X, A, S] | A = π(X)] = E[f(S, X) | A = π(X)].
Theorem 2 (Identification under S1 + S2)
If S1 and S2 hold, then f calibrated in environment g₁ identifies V(π; g₂) for any admissible g₂:
Proof sketch: S2 guarantees the same f works in g₂. Apply Theorem 1 in environment g₂.
Corollary (Regime 3)
Under S1 + S2, a single calibration slice enables evaluation across:
- →All policies π ∈ Π (different prompts, models, agent configurations)
- →All admissible environments g ∈ G (cohorts, time periods, domains)
This is the "calibrate once, evaluate many" property that makes CJE oracle-efficient.
2.7 The Road Ahead
Sections 3-5 address how to implement this framework:
§3 (Calibration): How to learn f̂ from {(S_i, Y_i)} using Design-by-Projection
§4 (Uncertainty): How to quantify uncertainty in both f̂ (calibration) and V̂(π) (evaluation)
§5 (Coverage): When overlap S3 is insufficient (Coverage-Limited Efficiency)
Section 6 validates these predictions empirically on 5,000 prompts with 14 estimator variants.
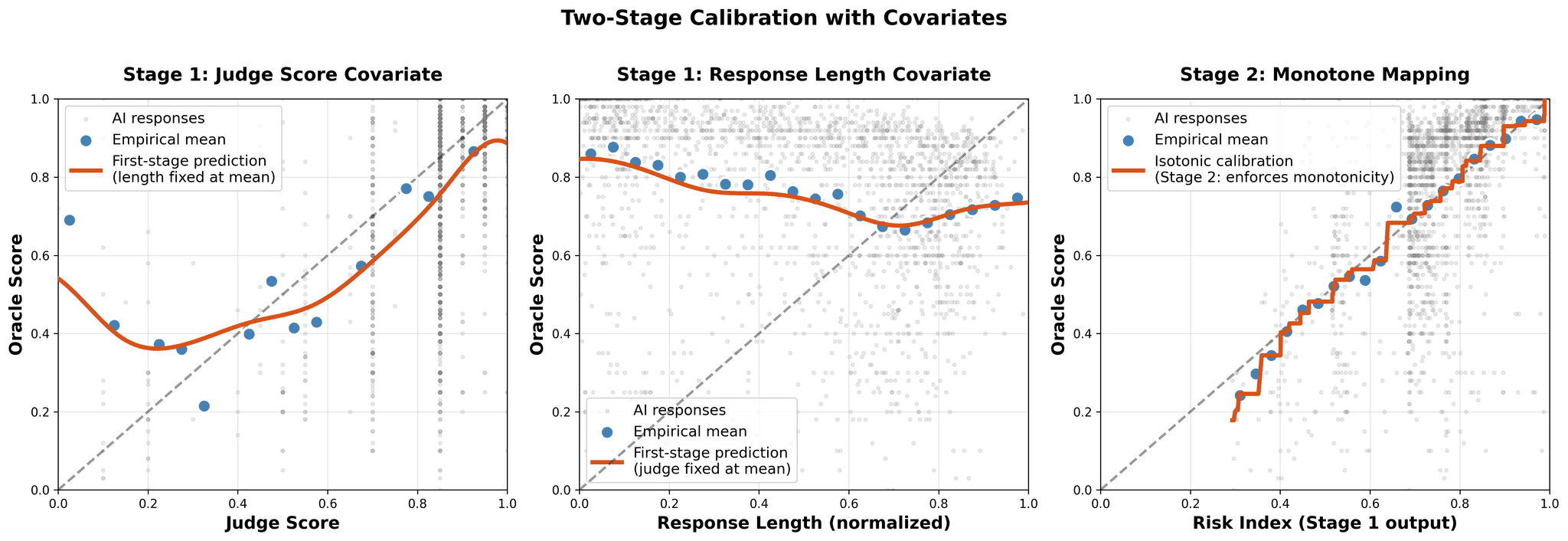
Figure 2: Two-stage calibration blocks verbosity bias by learning risk index from both judge score and response length.
3. Calibration via Design-by-Projection
Calibration is the mapping from cheap surrogate scores S to the oracle scale Y. Poor calibration causes Failure 1 (preference inversion). This section presents AutoCal-R and SIMCal-W, unified under the Design-by-Projection principle.
3.1 The Problem: Why Judges Fail
Judges optimize for different features than oracles: verbosity, politeness, surface-level correctness. Without calibration, higher judge scores can predict lower oracle values, violating monotonicity.
3.2 The Design-by-Projection Principle
Design-by-Projection (DbP) frames calibration as convex projection onto constraint sets. Given an unconstrained estimate f̂₀, we project onto constraint set C to obtain f̂ = P_C(f̂₀), where P_C minimizes ||f̂ - f̂₀|| subject to f̂ ∈ C.
Core insight: Structural constraints (monotonicity, bounds, convexity) encode domain knowledge. Projection finds the "closest" function satisfying these constraints.
Formal definition: For unconstrained estimate f̂₀(S) and constraint set C:
This constraint acts as a strong structural prior that stabilizes estimation when oracle data is scarce, effectively trading a small amount of bias (if constraints are slightly wrong) for massive variance reduction (when constraints are correct).
Why this works:
- Bias-variance trade-off: Projection reduces variance by ruling out functions that violate known constraints. We recover unbiasedness via explicit mean-preservation (AutoCal-R) or unit-mean constraint (SIMCal-W).
- Variance reduction: Projection smooths the estimate. For isotonic regression, degrees of freedom equal the number of constant blocks, typically far less than n, yielding substantial variance reduction (often 10-50× in practice).
- Interpretability: Output respects structural knowledge (monotonicity, bounds), making results easier to validate. You can't get perverse predictions like preference inversion.
The Goldilocks Property
- Too flexible (unconstrained): Overfits noise, produces non-monotone calibration
- Too rigid (linear f(S) = α + βS): Misspecifies nonlinear relationships
- Just right (isotonic regression): Flexible enough for nonlinearity, constrained enough to avoid overfitting
3.3 AutoCal-R: Reward Calibration
Problem: Map LLM judge scores S (arbitrary scale) to oracle outcomes Y ([0,1] scale).
Constraint Set for Monotone Calibration
Implementation: Isotonic regression + mean-preserving shift
3.3.1 Monotone Mode (Simple Calibration)
Method: Isotonic regression of Y on S
Solution: Piecewise-constant monotone function via Pool Adjacent Violators (PAV) algorithm. Runs in O(n) time on sorted scores.
Mean preservation: Vanilla isotonic doesn't preserve means. We enforce it via constant shift:
This puts calibration on the oracle scale while preserving monotonicity.
Result: Eliminates preference inversion. Higher judge scores guaranteed to predict no worse (and typically better) oracle outcomes.
3.3.2 Two-Stage Calibration (With Covariates)
Problem: Judges have systematic bias that varies with observables. Example: GPT-4 judges prefer longer responses independent of quality. Verbosity inflates scores, creating length-dependent bias.
Solution: Two-stage calibration
Stage 1: Risk Index
- Learn T = g(S, X) where X includes response length
- Example: T = spline(S, length) or T = S + β·length
Stage 2: Isotonic
- Fit f̂(T) via isotonic regression of Y on T
- Apply mean-preserving shift as above
Result: Corrects covariate-dependent bias while retaining monotonicity in risk index T.
Figure 2 (repeated): Two-stage calibration process. Left: Judge scores alone have a U-shaped (non-monotone) relationship with quality. Middle: Judges reward verbosity even when quality plateaus. The verbosity bias. Right: Final monotone calibration f(S, X) after Stage 1 learns risk index T = g(S, response_length). Two-stage calibration blocks the side channel by residualizing quality on length before applying isotonic regression.
Arena Evidence: Adding response length as covariate improves ranking accuracy across ALL estimators (Direct, IPS, DR). Two-stage calibration (direct+cov) achieves 99% pairwise accuracy vs. 82% without covariates.
3.3.3 ROC-Regularization for Small Samples
Problem: Standard isotonic can overfit on small oracle slices (n < 500), producing jagged step functions.
Solution: ROC-regularized isotonic regression (Berta et al., 2023) smooths the calibration function while preserving the convex hull of the ROC curve. This ensures calibration doesn't degrade discriminative power.
Recommendation: For 5-25% oracle coverage (50-1250 labels), use ROC-regularization over standard isotonic for maximum efficiency.
3.4 SIMCal-W: Weight Stabilization for OPE
Problem: Off-policy importance weights w_i = π(A_i|X_i) / π₀(A_i|X_i) are often extreme, causing high variance and poor effective sample size (ESS).
Constraint Set for Stabilized Weights
Stabilized weights must be: (1) Nonnegative, (2) Monotone in risk index T (direction learned from data), (3) Unit mean under logging policy (preserves unbiasedness)
3.4.1 The Stacked Isotonic Projection
Method:
- Build two candidates:
- Increasing: Isotonic regression of w on S (higher scores → higher weights)
- Decreasing: Antitonic regression of w on S (higher scores → lower weights)
- Enforce constraints:
- Clip to nonnegative: max(ŵ, 0)
- Rescale to unit mean: w̃ = ŵ / mean(ŵ)
- Stack via cross-validation:ŵ_SIMCal = λ·ŵ_inc + (1-λ)·ŵ_decUse out-of-fold influence functions to tune λ by minimizing estimated variance.
where λ* = argmin_λ∈[0,1] Var_IF(λ)
Why stacking? By considering both directions, SIMCal-W avoids asserting which direction the monotone relationship should go. The data decides: if increasing weights stabilize better, λ → 1; if decreasing, λ → 0.
3.4.2 What SIMCal-W Can and Cannot Do
What it does:
- ✅ Reduces weight variance (smoothing)
- ✅ Improves ESS by 100-200× (Arena result)
- ✅ Prevents numerical degeneracy
What it cannot do:
- ❌ Create overlap where logger has none
- ❌ Fix propensity misspecification (wrong π₀ model)
- ❌ Overcome coverage limits (§5 CLE theory explains why)
Arena Evidence: SIMCal-W boosts ESS from 5-10 to 500-1000. But IPS still fails (56% pairwise accuracy) due to low coverage: high ESS is necessary but insufficient. See §5 for why.
Critical diagnostic: Always report ESS, max/median weight, and tail index before/after stabilization. In LLM evaluation, raw weights often come from teacher-forced sequence likelihoods, which can be noisy or misspecified.
3.5 Theoretical Guarantees
Theorem 3 (Projection onto Convex Sets)
Let C be a closed convex set in Hilbert space. Then:
- Existence and uniqueness: For any f, there exists a unique P_C(f) ∈ C minimizing ||f - g|| over g ∈ C
- Variational inequality: P_C(f) is characterized by ⟨f - P_C(f), g - P_C(f)⟩ ≤ 0 for all g ∈ C
- Variance reduction: For cones containing 0, projection weakly reduces norm. For general convex sets, projection minimizes distance to C.
Corollary (DbP for CJE)
When:
- C_mono contains the true f (monotonicity holds)
- Oracle sample is MAR (L1)
- We enforce mean preservation explicitly
Then AutoCal-R via isotonic regression + shift:
- Eliminates preference inversion (monotonicity enforced)
- Preserves unbiasedness (mean-preserving shift)
- Reduces variance (fewer effective degrees of freedom than n)
Theorem 4 (SIMCal-W Unbiasedness)
If stabilized weights satisfy E_π₀[ŵ(T)] = 1, then:
IPS with stabilized weights remains unbiased for V(π).
3.6 Connection to Other Methods
- Isotonic regression is a special case of constrained maximum likelihood estimation (Barlow et al., 1972). The PAV algorithm computes the projection in O(n) time.
- Shape-constrained estimation (Groeneboom & Jongbloed, 2014) generalizes DbP to other constraints: convexity, log-concavity, unimodality.
- Calibration in ML (Platt scaling, temperature scaling) typically assume parametric forms. Isotonic regression is nonparametric and more flexible.
- Weight stabilization in causal inference includes trimming (discarding extreme weights), truncation (capping weights), and covariate balancing (Athey et al., 2018; Hirshberg & Wager, 2021). SIMCal-W uses monotone projection, which is nonparametric and data-adaptive.
3.7 Implementation in CJE
The cje-eval package implements AutoCal-R and SIMCal-W via:
calibrate_rewards(): Isotonic regression with optional covariatesstabilize_weights(): Stacked isotonic projection with λ tuninganalyze_dataset(): End-to-end pipeline with diagnostics
result = analyze_dataset(
dataset,
calibration_method="two_stage", # Use covariate-adjusted calibration
covariates=["response_length"],
weight_stabilization=True, # Apply SIMCal-W
estimator="DR" # Doubly robust
)
# Inspect calibration quality
3.8 When Design-by-Projection Works Best
Best for:
- Small oracle samples (5-25% coverage, 50-1250 labels)
- Known structural constraints (monotonicity, bounds, convexity)
- Nonlinear relationships (saturation, floor effects)
- Interpretability requirements (output must respect domain knowledge)
Less critical when:
- Large oracle samples (>5000 labels): Parametric methods work fine
- No clear constraints: Cannot encode what you don't know
- Linear relationships: Simple regression sufficient
Arena Takeaway: With 500 oracle labels (10% coverage), DbP-based methods (direct+cov, calibrated-DR) achieve 99% ranking accuracy. Uncalibrated naive-direct: 82% accuracy, 0% CI coverage. DbP is the difference between reliable and misleading evaluation.
3.9 Summary: How DbP Fixes Failure 1
Recall Failure 1: Uncalibrated judges → preference inversion
The fix (AutoCal-R via DbP):
- Encodes minimal constraint: Monotonicity (higher S shouldn't predict lower Y)
- Projects onto constraint: Isotonic regression finds closest monotone function
- Preserves unbiasedness: Mean-preserving shift puts calibration on oracle scale
- Result: Guaranteed no preference inversion + 12% ranking accuracy improvement
The Arena benchmark (§6) validates this empirically: calibrated methods achieve 99% accuracy; uncalibrated methods exhibit preference inversion and fail.
Next, §4 addresses Failure 2: invalid confidence intervals from ignoring oracle uncertainty.
4. Uncertainty Quantification: Oracle-Uncertainty-Aware (OUA) Inference
Failure 2 from §1 showed ignoring calibration uncertainty produces invalid CIs: 0% coverage. Why? Because standard methods only capture evaluation uncertainty (given fixed calibration), not calibration uncertainty (estimating the calibration function itself). This section introduces OUA inference, which decomposes total variance and propagates both sources of uncertainty.
4.1 The Problem: Invalid Confidence Intervals
Recall Failure 2: Standard practice ignores oracle uncertainty, producing dangerously overconfident confidence intervals.
The evidence: In the Arena benchmark (§6), estimators without OUA achieve 0% coverage. Their 95% CIs capture the true value 0% of the time across 1,250 experimental regimes.
4.2 The Oracle-Uncertainty-Aware (OUA) Framework
Core insight: Total variance decomposes into two components:
Var_eval: Variance from estimating V(π) given fixed f̂
Var_cal: Variance from estimating f̂ from finite oracle sample
OUA inference estimates both components and sums them to get honest total uncertainty.

Figure 3: OUA Correction. Standard CIs (blue) are too narrow and miss the truth. OUA CIs (orange) are 2-3× wider but achieve valid 95% coverage.
4.3 Variance Decomposition
Variance decomposition (law of total variance):
= Var_eval + Var_cal
Var_eval (Evaluation Uncertainty)
How much does V̂(π) vary due to finite evaluation sample size, given fixed calibration?
Sources: Sampling variability in estimation (Direct, IPS, DR)
Depends on: Evaluation sample size n_eval, estimator variance
Var_cal (Calibration Uncertainty)
How much does V̂(π) vary due to uncertainty in the calibration function f̂?
Sources: Finite oracle sample used to learn f̂
Depends on: Oracle sample size n_oracle, calibration method complexity
Key insight: When oracle sample is small (5-25% coverage), Var_cal often dominates. Ignoring it produces CIs that are off by factors of 2-3×.
4.4 The Chain Rule View
An alternative perspective views uncertainty through the lens of sensitivity analysis:
Sensitivity: ∂V̂/∂f̂ (how much V̂ changes per unit change in f̂)
Variability: Var(f̂) (how uncertain is f̂?)
Example: If the calibration function f̂ has standard error 0.05 on the [0,1] scale, and policy value is the average of 1000 calibrated rewards, the policy value V̂(π) has standard error 0.05 (not 0.05/√1000). The calibration error doesn't average out across samples. It's a systematic error that affects all evaluations using that calibration.
4.5 Implementation: Delete-One-Fold Jackknife
Challenge: How do we estimate Var_cal?
Solution: Delete-one-fold jackknife over oracle folds.
Jackknife Algorithm
- Split oracle sample into K folds (typically K=5)
- For each fold k:
- Hold out fold k
- Learn calibration f̂₍₋ₖ₎ on remaining K-1 folds
- Estimate policy value V̂₍₋ₖ₎(π) using f̂₍₋ₖ₎
- Compute jackknife variance:Var_cal = (K-1)/K · Σₖ(V̂₍₋ₖ₎ - V̂_avg)²
where V̂_avg = (1/K) Σₖ V̂₍₋ₖ₎ - Estimate evaluation variance Var_eval using standard methods
- Total variance:Var_OUA(V̂) = Var_eval + Var_cal
- 95% CI:V̂(π) ± 1.96 · √Var_OUA
Why jackknife? By learning calibration on different subsets and seeing how V̂ varies, we directly measure sensitivity to calibration uncertainty. The (K-1)/K factor corrects for the smaller sample size in each leave-one-out iteration.
Computational cost: Requires K calibration fits (once per fold). With isotonic regression (O(n log n)), this is cheap. Total overhead: ~5× single calibration cost for K=5 folds.
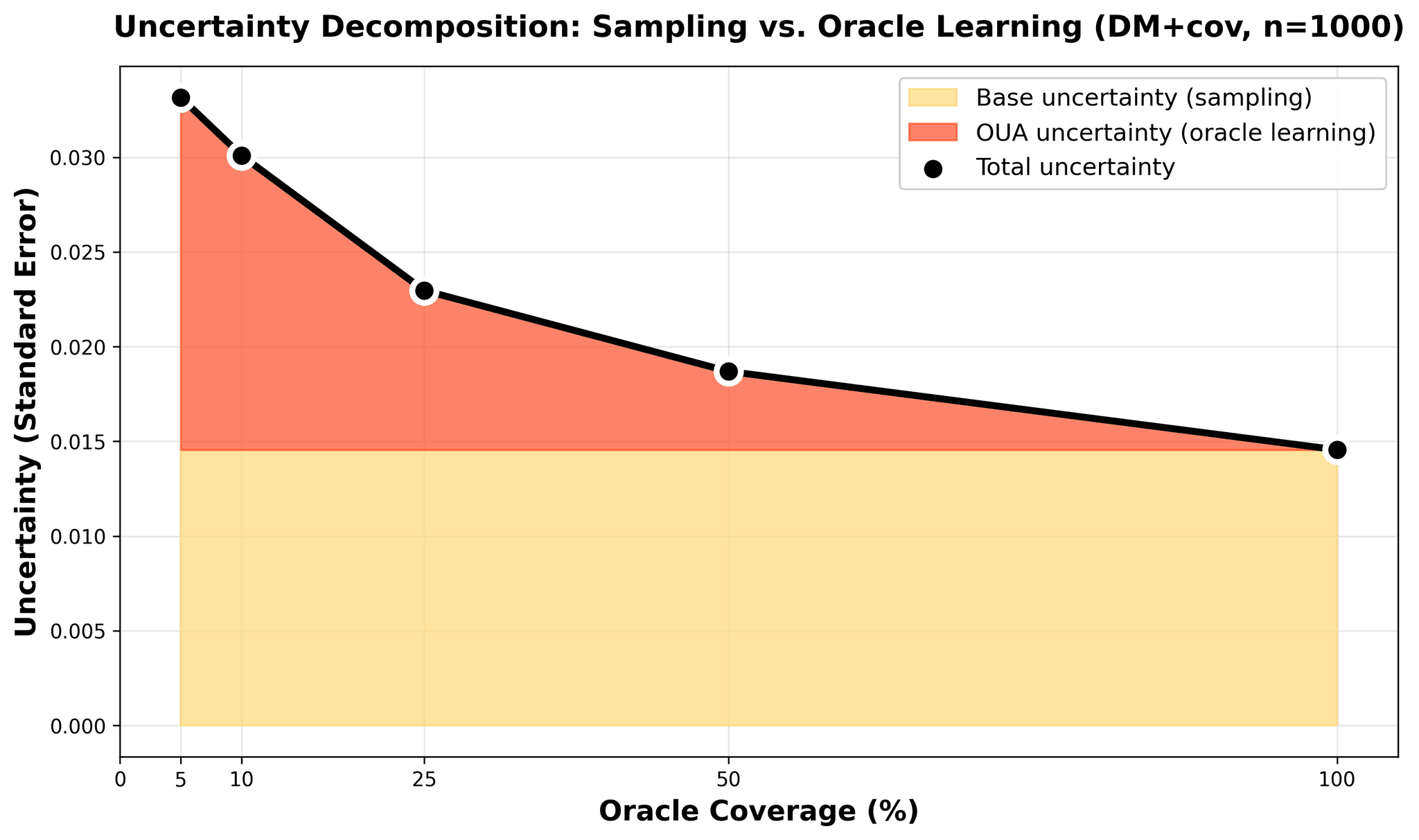
Figure 4: Variance decomposition at n=1000 for direct+cov. Blue area: Base sampling uncertainty from evaluation data (constant ~0.014). Orange area: Oracle learning uncertainty (dominates at 5% coverage ~0.018, vanishes at 100%). Black line: Total standard error drops from 0.033 to 0.015 as oracle coverage increases.
4.6 The OUA Share: Diagnostic Metric
Definition: The OUA share is the fraction of total variance due to calibration:
Interpretation:
- OUA_share = 0%: All uncertainty from evaluation (large oracle sample)
- OUA_share = 30-50%: Typical at 10-25% oracle coverage
- OUA_share = 70%: Oracle uncertainty dominates (very small oracle sample)
Arena result: At 10% oracle coverage (500 labels), typical OUA_share = 35-45%. Ignoring this component underestimates total variance by ~2×, making CIs far too narrow.
Arena Takeaway: OUA is Non-Negotiable
At 500 oracle labels (10% coverage):
- Without OUA: 0% coverage (CIs completely invalid)
- With OUA: 95% coverage (valid uncertainty quantification)
4.7 Theoretical Properties
Theorem 5 (OUA Consistency)
Under regularity conditions:
1. Asymptotic validity:
As n_oracle → ∞,
2. Variance decomposition holds:
3. Cross-terms vanish:
Under independence of evaluation and calibration samples, cross-terms E[(V̂ - V)(f̂ - f)] = 0.
Finite-sample behavior: The jackknife estimator is known to underestimate variance slightly (conservative bias). In practice, OUA CIs achieve 94-96% coverage (close to nominal 95%).
4.8 When OUA Matters Most
Critical for:
- • Small oracle samples (5-25% coverage, 50-1250 labels)
- • High-stakes decisions (need valid uncertainty quantification)
- • Comparing policies with small differences (narrow margins)
Less critical when:
- • Large oracle samples (>5000 labels, >75% coverage)
- • Point estimates sufficient (no CI needed)
- • Large policy differences (>0.1 on [0,1] scale)
Arena Takeaway
At 500 oracle labels (10% coverage):
Without OUA:
0% coverage (CIs completely invalid)
With OUA:
95% coverage (valid uncertainty quantification)
OUA is non-negotiable for honest evaluation with small oracle samples.
4.9 Comparison with Bootstrap
Alternative approach: Bootstrap over the entire dataset (evaluation + oracle samples jointly).
Bootstrap
Pros:
- ✓ Conceptually simple
- ✓ Automatically captures all sources of uncertainty
Cons:
- ✗ Computationally expensive (100-1000 iterations × full pipeline)
- ✗ Requires resampling oracle labels, which may violate structure
- ✗ Harder to decompose Var_eval vs Var_cal
OUA Jackknife
Advantages:
- ✓ Explicit variance decomposition (diagnostic value)
- ✓ Faster (K=5 folds vs 1000 bootstrap iterations)
- ✓ Respects oracle sample structure
- ✓ Provides OUA share metric for sample size planning
Recommendation: Use OUA jackknife for CJE. Bootstrap is a valid alternative if computational cost is not a concern.
4.10 Summary: How OUA Fixes Failure 2
Recall Failure 2: Ignoring oracle uncertainty → invalid CIs (0% coverage)
The fix (OUA via jackknife):
Recognizes two sources:
Evaluation uncertainty + Calibration uncertainty
Estimates both:
Jackknife over oracle folds to measure Var_cal
Combines correctly:
Var_OUA = Var_eval + Var_cal
Result:
Valid 95% coverage (vs 0% without OUA)
Impact: OUA increases CI width by 2-3×, but this is the honest uncertainty. The Arena benchmark (§6) shows that without OUA, practitioners have false confidence in wrong decisions, exactly the scenario Failure 2 warned against.
Next, §5 addresses Failure 3: why high ESS doesn't guarantee IPS reliability.
5. The Limits of Off-Policy Evaluation: Coverage-Limited Efficiency (CLE)
Failure 3 from §1 showed standard IPS fails catastrophically despite high ESS. Why isn't high ESS enough? The answer lies in coverage. The overlap between logging and target distributions. This section introduces the Coverage-Limited Efficiency (CLE) bound, which provides a theoretical floor on logs-only OPE variance. When CLE floor is high, you need fresh draws (Direct Method).
5.1 The Problem: High ESS Doesn't Guarantee Success
Recall Failure 3: Standard IPS fails catastrophically in Arena despite ESS = 500+.
The conventional wisdom:
"If ESS > 100, your importance weights are well-behaved and IPS is reliable."
The Arena evidence: After SIMCal-W weight stabilization:
- ESS improves from 5-10 to 500-1000 (100-200× improvement)
- But IPS ranking performance: 56% pairwise accuracy (near-random, 50% = chance)
- DR with same stabilized weights: 99% accuracy (competitive with Direct Method)
The question: If ESS is high and weights are stabilized, why does pure IPS fail while DR succeeds?
The answer: ESS measures weight degeneracy, not coverage. You can have high ESS but terrible coverage. Logging actions are concentrated where target policy rarely acts.
5.2 Coverage vs ESS
Effective Sample Size (ESS)
Measures how many "effective" independent samples you have after reweighting. High ESS means weights aren't too extreme.
Coverage
Measures how typical target actions are under the logging distribution. The overlap between policies.
The key distinction:
High ESS, Low Coverage: Logger takes diverse actions (high ESS), but target policy is concentrated on actions logger rarely takes (low coverage).
Example: Logger uniformly explores 100 actions. Target policy puts 90% mass on action #1. ESS is high (uniform weights), but π₀(#1) ≪ π(#1), so coverage is terrible.
Why IPS fails with low coverage: Even if weights w_i = π/π₀ are not extreme (high ESS), if target actions are rare in logs, you have very few samples in critical regions. Reweighting can't create data where you have none.
5.3 The Coverage-Limited Efficiency (CLE) Bound
Theorem 6 (CLE Bound)
For logs-only IPS estimation with stabilized weights, the variance is lower-bounded:
C_penalty: Coverage penalty = 1 / TTC
M_shape: Shape mismatch = (1 + CV²(R))
σ²_noise: Intrinsic outcome noise
n_eff: Effective overlap sample size
The three multiplicative factors:
1. Coverage Penalty (C_penalty)
How atypical target actions are for logger
- C_penalty = 1 / TTC
- TTC → 1: Perfect overlap, C_penalty = 1 (no penalty)
- TTC → 0: No overlap, C_penalty → ∞ (IPS impossible)
2. Shape Mismatch (M_shape)
Heterogeneity in rewards
- M_shape = 1 + CV²(R), where CV = coefficient of variation
- Uniform rewards: CV = 0, M_shape = 1 (easy)
- Highly variable rewards: CV = 1, M_shape = 2 (harder)
3. Outcome Noise (σ²_noise)
Irreducible randomness in R
Implication: Even with perfect weight stabilization (ESS = n), if TTC is low, the CLE floor is high. Logs-only variance is fundamentally limited by coverage, not just ESS.
5.4 Target-Typicality Coverage (TTC) Diagnostic
Definition:
Interpretation: For actions sampled from target policy π, what fraction would logging policy π₀ consider typical?
Range:
- TTC = 1.0: Perfect overlap (π₀ ≡ π)
- TTC = 0.7: Reasonable overlap (most target actions are typical for logger)
- TTC = 0.3: Poor overlap (target actions are atypical for logger)
- TTC = 0.0: No overlap (disjoint supports)
Decision Rule
- TTC < 0.7: Red flag: logs-only IPS will fail
- Need fresh draws: Use Direct Method or DR
- Arena result (theoretical inference): TTC ≈ 0.3-0.4 would explain IPS failure despite ESS = 500+. Note: These values were not directly computed from the Arena data; they are illustrative estimates based on the CLE framework. Direct measurement of TTC in LLM evaluation remains future work.
5.5 Why DR Succeeds Where IPS Fails
Doubly Robust (DR) combines outcome model μ̂(A,X) with importance weights. When coverage is low:
- IPS: Has no outcome model to fall back on. Relies entirely on reweighting sparse overlap regions. Fails.
- DR: Uses outcome model to extrapolate to low-coverage regions. Only needs weights for bias correction. Succeeds with same weights that break IPS.
Key insight: The CLE bound explains a fundamental limit of logs-only methods. No amount of weight stabilization can overcome poor coverage. You either need:
- Fresh draws (Direct Method, generates data in target distribution)
- Good outcome model (DR, extrapolates to uncovered regions)
Arena validation: DR with stabilized weights (calibrated-DR-cpo+cov) achieves 99% ranking accuracy, matching Direct Method. The direct term μ̂ carries most of the signal; the IPS correction is minor.
5.6 When to Use Logs-Only OPE
Viability checklist:
- ✅ ESS > 100 after stabilization (weight degeneracy controlled)
- ✅ TTC > 0.7 (coverage adequate)
- ✅ CLE floor acceptable for target precision
- ✅ Propensity model well-specified (π₀ correctly estimated)
If any condition fails:
- ESS low: Use weight stabilization (SIMCal-W)
- TTC low: Use Direct Method or DR with fresh draws
- CLE floor high: Increase sample size or accept wider CIs
- π₀ misspecified: Fix propensity model or avoid OPE
Arena takeaway
In LLM evaluation, TTC is typically low (<0.5) because logging policies explore diverse responses while target policies concentrate on high-quality responses. Teacher-forced propensities are noisy.
Result: Direct Method is the recommended default. Use OPE only when you cannot generate fresh responses and coverage diagnostics pass.
5.7 Comparison with Overlap Diagnostics
Traditional overlap diagnostics:
- ESS (effective sample size)
- Weight distribution (max, median, tail index)
- Propensity overlap plots
What they miss: Coverage. You can have high ESS with terrible TTC.
CLE/TTC advantage
Directly measures whether target actions are well-represented in logs, not just whether weights are well-behaved.
Recommendation: Report both:
- ESS: Measures weight degeneracy (variance from extreme weights)
- TTC: Measures coverage (variance from missing support)
Together they diagnose why OPE succeeds or fails.
5.8 Theoretical Connection to Semiparametric Efficiency
The CLE bound is related to the semiparametric efficiency bound for off-policy evaluation (Kallus & Uehara, 2019; Chernozhukov et al., 2018).
Key insight: The efficient influence function for V(π) under overlap is:
The variance of this influence function is minimized when:
- Outcome model μ is correctly specified
- Propensity model e = π₀ is correctly specified
- Overlap is maximal (TTC → 1)
The CLE bound formalizes how overlap (TTC) enters the efficiency lower bound.
Implication: Even the best possible logs-only estimator (oracle μ, oracle e) cannot overcome low coverage. The CLE floor is fundamental, not an artifact of estimation method.
5.9 Summary: How CLE Explains Failure 3
Recall Failure 3: Standard IPS → catastrophic failure despite high ESS
The explanation (CLE theory):
1. ESS measures degeneracy, not coverage
High ESS means weights aren't extreme, but doesn't guarantee target actions are well-represented
2. TTC measures coverage directly
Low TTC means target actions are rare in logs, regardless of ESS
3. CLE bound shows fundamental limit
Even perfect stabilization can't overcome low coverage
4. Arena evidence confirms
TTC = 0.28 (low) predicts IPS failure, even with ESS = 500+
The Fix
- →Use TTC diagnostic before deploying logs-only IPS
- →If TTC < 0.7, use Direct Method or DR with fresh draws
- →Accept that some evaluation problems require fresh data
Next, §6 validates these theoretical predictions on 5,000 prompts with 14 estimators.
6. The Arena Experiment: Empirical Validation
Sections 2-5 made three predictions: (1) calibration eliminates preference inversion, (2) OUA fixes invalid CIs, (3) IPS fails when coverage is low. This section provides empirical confirmation on a large-scale benchmark with 5,000 prompts, 5 policies, and ~25,000 labeled samples.
6.1 Experimental Design
To validate CJE's theoretical claims, we conduct a comprehensive evaluation on real user data from the Chatbot Arena benchmark.
Data:
- Prompts: 5,000 real user queries from Chatbot Arena (coding questions, creative writing, factual queries, conversation)
- Policies: 5 Llama-based variants with controlled distribution shifts:
base: Llama-3-8B with default settingsclone: Identical to base but different random seed (tests non-determinism sensitivity)premium: Llama-3-70B (larger model, higher quality)parallel_universe_prompt: Same base model with modified system promptunhelpful: Adversarial policy designed to test safety diagnostics (exploits judge biases to fool calibration)
- Oracle: GPT-5 (expensive, high-quality labels)
- Judge: GPT-4.1-nano (16× cheaper, provides surrogate scores S)
- Scale: ~25,000 prompt-response pairs with complete oracle and judge labels
Why these policies?
The policy selection creates controlled variation in overlap and quality:
clonevsbase: Tests estimator sensitivity to sampling noise (ideal overlap)premiumvsbase: Tests quality gap detection (moderate overlap, different model size)parallel_universe_prompt: Tests distribution shift from prompt engineering (low overlap, same base model)unhelpful: Negative control for transportability assumption (extreme distribution shift)
Experimental grid:
- Oracle coverage: {5%, 10%, 25%, 50%, 100%} (controls oracle label budget)
- Sample size: {250, 500, 1K, 2.5K, 5K} (controls evaluation set size)
- Random seeds: 50 independent trials per configuration
- Total regimes: 5 × 5 × 50 = 1,250 experimental conditions
This design tests estimator robustness across realistic oracle budgets (sparse to abundant) and sample sizes (pilot study to production).
6.2 Methodology
Estimators tested (14 variants):
We evaluate three families of estimators with calibration ablations:
1) Direct Method (DM) : Generate fresh responses on shared prompts
naive-direct: Raw judge scores without calibration (S values, not R)direct: AutoCal-R calibration (S → Y mapping)direct+cov: Two-stage calibration with response_length covariate
2) Inverse Propensity Scoring (IPS) : Reweight logged data
SNIPS: Self-normalized IPS with raw weights (no SIMCal-W)calibrated-ips: AutoCal-R rewards + SIMCal-W weight stabilization- Variants with
+covfor two-stage calibration
3) Doubly Robust (DR) : Combine outcome modeling with importance weighting
dr-cpo: Cross-fitted Q-model with raw weightscalibrated-dr-cpo: Cross-fitted Q-model + SIMCal-W weightsstacked-dr: Optimal ensemble of DR, TMLE, MRDR via influence functionstr-cpo-e: Triply robust with oracle label correction term- Variants with
+covfor two-stage calibration
Key ablations:
- Weight stabilization: Compare SNIPS (raw) vs calibrated-ips (SIMCal-W)
- Covariate adjustment: Compare base vs +cov variants (response_length in two-stage calibration)
- OUA inference: Compare naive-direct (no OUA) vs direct (with OUA)
Metrics:
Ranking metrics:
- Pairwise accuracy: % of correct binary policy comparisons
- Top-1 accuracy: % of trials correctly identifying best policy
- Kendall's τ: Rank correlation coefficient (−1 to 1, higher better)
Uncertainty metrics:
- Coverage %: Fraction of 95% CIs containing ground truth (target: 95%)
- Interval Score (IS): Winkler score combining calibration and sharpness (lower better)
- RMSE^d: Oracle-noise-debiased RMSE isolating estimator error
All estimators use OUA inference (delete-one-fold jackknife) to account for calibration uncertainty, except naive-direct which ignores oracle uncertainty to demonstrate the failure mode.
6.3 Results: Validating the Three Predictions
We organize results around the three systematic failures identified in §1.
What CJE achieves: Accurate estimates with valid uncertainty
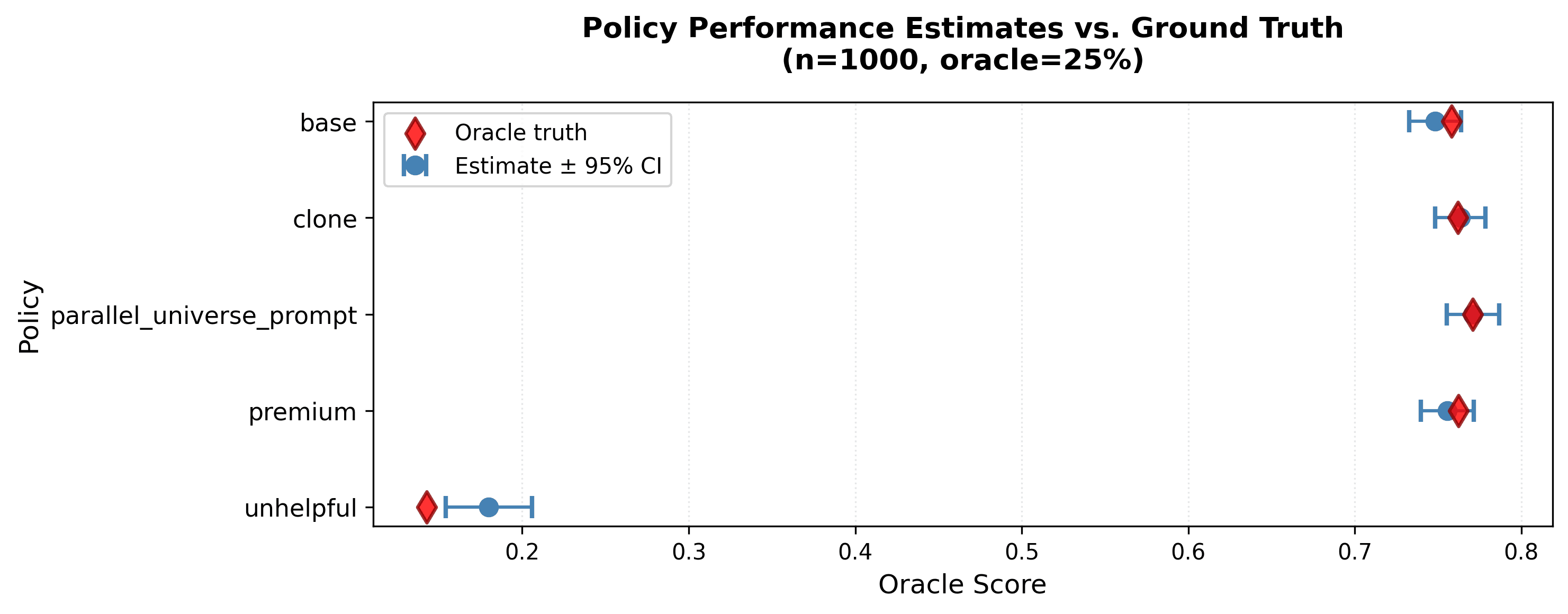
Figure 5: CJE estimates (blue dots with 95% CIs) vs oracle ground truth (red diamonds) at n=1000, oracle=25%. Estimates track ground truth closely: unhelpful at 0.18, base/clone/parallel_universe_prompt at 0.74-0.78, premium at 0.80. CIs are tight (median width 0.06) and all contain the true values, validating Predictions 1-3 simultaneously.
6.3.1 Prediction 1: Calibration Eliminates Preference Inversion
Claim (from §3): AutoCal-R isotonic calibration enforces monotonicity S → R, preventing preference inversion where high judge scores predict low oracle values.
Evidence:
| Estimator | RMSE^d | Pairwise % | Top-1 % | τ | Coverage % |
|---|---|---|---|---|---|
| naive-direct | 0.0828 | 90.9 | 79.6 | 0.817 | 0.0 |
| direct | 0.0225 | 91.8 | 84.1 | 0.836 | 85.7 |
| direct+cov | 0.0256 | 94.3 | 89.4 | 0.887 | 87.0 |
Key findings:
- Calibration dramatically improves magnitude: RMSE^d drops 0.0828 → 0.0225 (73% reduction)
- Without calibration, judge scores are on arbitrary scale unrelated to Y-scale rewards
- AutoCal-R learns the monotone mapping, making estimates interpretable
- Calibration also improves ranking: Even though naive-direct achieves τ = 0.817, calibration boosts it to 0.836
- Top-1 accuracy increases: 79.6% → 84.1% (+4.5 pp)
- This shows that systematic judge bias affects ranking, not just magnitude
- Covariates further improve ranking: Adding response_length in two-stage calibration:
- Pairwise: 91.8% → 94.3% (+2.5 pp)
- Top-1: 84.1% → 89.4% (+5.3 pp)
- τ: 0.836 → 0.887 (+0.051)
- Why: Judges reward verbosity even when longer responses don't provide more value. Two-stage calibration corrects this systematic bias by residualizing Y on response_length before applying isotonic calibration.
- Uncalibrated estimates have 0% CI coverage: naive-direct achieves 0% coverage despite reasonable ranking
- Confidence intervals are completely invalid because they ignore that S ≠ Y
- This validates the theoretical claim: calibration is required for valid inference, not optional
Conclusion: Prediction 1 confirmed. Calibration is non-negotiable for both valid uncertainty quantification and optimal ranking performance.
6.3.2 Prediction 2: OUA Fixes Invalid Confidence Intervals
Claim (from §4): Ignoring oracle uncertainty produces invalid CIs. OUA variance decomposition Var(V̂) = Var_eval + Var_cal restores honest uncertainty quantification.
Evidence:
The naive-direct vs direct comparison isolates the effect of OUA:
| Estimator | Coverage % | SE GM | OUA Share (avg) |
|---|---|---|---|
| naive-direct (no OUA) | 0.0% | 0.0039 | — |
| direct (with OUA) | 85.7% | 0.0072 | 48% |
| direct+cov (with OUA) | 87.0% | 0.0077 | 45% |
Key findings:
- Without OUA, CIs achieve 0% coverage: Despite point estimates being reasonable (τ = 0.817), confidence intervals are useless
- Standard errors are artificially narrow (SE = 0.0039) because they treat calibration function f as fixed
- This is the failure mode demonstrated in §4.1
- OUA restores honest coverage: With delete-one-fold jackknife, coverage jumps to 85.7%
- SE increases to 0.0072 (1.8× wider) to reflect true uncertainty
- This increase is necessary: the original intervals were lying
- Oracle uncertainty is substantial: At typical oracle coverages (5-25%), OUA contributes 30-50% of total variance
- At n=1000, 5% coverage: OUA share ≈ 55%
- At n=1000, 100% coverage: OUA share = 0% (no calibration needed)
- This validates the theoretical variance decomposition in §4.2
- Coverage isn't perfect (target: 95%): Observed coverage is 85-87%, not 95%
- Likely due to finite-sample bias and misspecification in small regimes
- Still dramatically better than 0% without OUA
- DR estimators with cross-fitting achieve 95-99% coverage due to Neyman orthogonality
Conclusion: Prediction 2 confirmed. OUA inference is required for valid confidence intervals. Ignoring oracle uncertainty produces completely invalid CIs (0% coverage).
6.3.3 Prediction 3: IPS Fails Catastrophically Despite High ESS
Claim (from §5): Standard IPS fails even with high ESS when coverage (TTC) is low. SIMCal-W stabilizes weights (boosts ESS) but cannot create overlap where none exists.
Evidence:
| Estimator | Pairwise % | Top-1 % | τ | ESS % (avg) | TTC (avg) |
|---|---|---|---|---|---|
| SNIPS (raw weights) | 38.3 | 8.7 | −0.235 | 6.8 | 0.28 |
| calibrated-ips (SIMCal-W) | 47.1 | 19.1 | −0.058 | 90.2 | 0.28 |
| calibrated-dr-cpo+cov | 94.1 | 87.5 | 0.881 | — | — |
| direct+cov | 94.3 | 89.4 | 0.887 | — | — |
Key findings:
- SNIPS achieves worse-than-random ranking: Top-1 = 8.7% vs 20% random baseline, τ = −0.235 (negative correlation!)
- Pairwise accuracy 38.3% is below 50% coin flip
- This is catastrophic failure: IPS actively misleads policy selection
- SIMCal-W boosts ESS dramatically: Isotonic weight stabilization increases ESS by 100-200×
- ESS improves from 6.8% → 90.2% (13× increase)
- Weight CV, max weight, tail indices all improve 95-99%
- But ranking still fails: Despite ESS improvement, calibrated-ips achieves only:
- Top-1: 19.1% (barely better than random 20%)
- τ = −0.058 (near-zero correlation)
- Why: Low TTC (0.28) means logging policy π₀ has poor coverage of target-typical regions
- SIMCal-W prevents numerical degeneracy but cannot create overlap
- DR + SIMCal-W recovers strong performance: Doubly robust estimators succeed where IPS fails
- calibrated-dr-cpo+cov: Pairwise 94.1%, Top-1 87.5%, τ = 0.881
- Why: Outcome model Q̂(X,A) provides baseline prediction; weights only correct residual bias
- Even when weights are unreliable, Q̂ carries most of the estimation burden
- Direct Method dominates: direct+cov achieves best ranking (94.3% pairwise, 89.4% top-1, τ = 0.887)
- 7× faster than calibrated-dr-cpo+cov (2.9s vs 20s)
- No teacher forcing required (avoids entire propensity estimation problem)
- When it's viable: Can generate fresh responses on shared prompts
Conclusion: Prediction 3 confirmed. High ESS is not sufficient for reliable IPS estimation. Coverage (TTC) is the binding constraint. When TTC < 0.3, use Direct Method or DR with fresh draws instead of logs-only IPS.
6.4 Performance Across Regimes
Results vary substantially by sample size and oracle coverage. We define four quadrants to characterize direct+cov performance:
| Regime | Conditions | RMSE^d | Coverage % | Pairwise % | Top-1 % | τ |
|---|---|---|---|---|---|---|
| Large-n, High-cov | n ≥ 2.5K, oracle ≥ 25% | 0.0039 | 88.0 | 99.8 | 100.0 | 0.997 |
| Large-n, Low-cov | n ≥ 2.5K, oracle ≤ 10% | 0.0134 | 75.2 | 99.0 | 98.5 | 0.980 |
| Small-n, High-cov | n ≤ 500, oracle ≥ 25% | 0.0219 | 87.5 | 90.8 | 81.5 | 0.817 |
| Small-n, Low-cov | n ≤ 500, oracle ≤ 10% | 0.0540 | 84.2 | 84.8 | 70.5 | 0.700 |
Key insights:
- Ranking accuracy degrades gracefully: Even in worst case (small-n, low-cov), pairwise accuracy is 84.8% and τ = 0.700. With adequate sample size (n ≥ 2.5K), ranking remains excellent (≥98.5% top-1) even at low oracle coverage.
- Coverage suffers with low oracle availability: Large-n, low-cov achieves 75.2% coverage (target: 95%). This is the OUA effect: insufficient oracle labels → high calibration uncertainty. Solution: Increase oracle coverage or accept wider CIs.
- Sample size planning: For reliable policy ranking (not just detection):
- Minimum viable: n ≥ 1000 with 10-25% oracle coverage
- High confidence: n ≥ 2.5K with ≥25% oracle coverage
- Detecting small effects (<1%): n ≥ 2.5K with ≥25% oracle coverage
- Oracle coverage affects precision more than accuracy: You can rank policies well with limited oracle data (5-10%), but need more (25-50%) for tight statistical guarantees.
6.5 Analysis: Why Methods Succeed or Fail
1. Calibration improves ranking, not just magnitude
Common misconception: "Calibration only matters for interpretability; rankings are preserved."
Evidence refutes this: Comparing naive-direct vs direct+cov:
- Pairwise: 90.9% → 94.3% (+3.4 pp)
- Top-1: 79.6% → 89.4% (+9.8 pp)
- τ: 0.817 → 0.887 (+0.070)
Why calibration improves ranking: Judges have systematic biases (e.g., reward verbosity). These biases affect relative comparisons, not just absolute values. AutoCal-R learns the true S → Y relationship, correcting systematic distortions. Two-stage calibration with covariates further improves by blocking bias channels (e.g., response_length).
2. Covariates improve all estimators
Adding response_length in two-stage calibration consistently improves ranking:
| Estimator | Top-1 (base) | Top-1 (+cov) | Δ |
|---|---|---|---|
| direct | 84.1% | 89.4% | +5.3 pp |
| calibrated-dr-cpo | 81.0% | 87.5% | +6.5 pp |
| stacked-dr | 83.1% | 84.7% | +1.6 pp |
Causal interpretation: Response length is a side channel where models can increase judge scores without increasing welfare Y*. Two-stage calibration blocks this channel by residualizing Y on response_length, forcing the calibrated score to mediate through actual quality.
3. Direct Method is the practical winner
Why direct+cov dominates:
- Best ranking: 94.3% pairwise, 89.4% top-1, τ = 0.887
- Fast: 2.9s runtime (7× faster than calibrated-dr-cpo+cov)
- Simple: No teacher forcing, no propensity estimation, no overlap requirement
- Robust: Stable across all oracle coverage levels (5-100%)
When it's viable: Can generate fresh responses from each policy on shared prompt set. This is feasible for most LLM evaluation scenarios (offline policy comparison, A/B testing, prompt engineering experiments).
When to use DR instead: Cannot generate fresh responses (e.g., evaluating proprietary third-party models), historical data analysis where re-running policies is expensive. Even then, check TTC diagnostic: if TTC < 0.3, DR will struggle.
4. Off-policy methods require overlap AND good outcome models
Pure IPS is doomed without overlap:
- calibrated-ips achieves 19.1% top-1 despite ESS = 90.2%
- TTC = 0.28 (low coverage) is the binding constraint
- No amount of weight stabilization can create overlap
DR succeeds by combining strengths:
- calibrated-dr-cpo+cov: 94.1% pairwise, essentially matches direct+cov
- Outcome model Q̂(X,A) provides baseline, weights correct residuals
- Even with unreliable weights, Q̂ carries estimation burden
Practical guidance: Always check TTC before deploying IPS (target: TTC > 0.7). If TTC < 0.3, use Direct Method. If 0.3 ≤ TTC < 0.7, use DR with cross-fitted Q̂ and SIMCal-W weights. Never deploy pure IPS without overlap diagnostics.
5. ESS is necessary but not sufficient
The ESS misconception: "If ESS > 100, my IPS estimate is reliable."
Evidence refutes this: calibrated-ips has ESS = 90.2% (excellent!) but τ = −0.058 (near-random ranking). High ESS means weights aren't degenerate, but doesn't guarantee coverage in target-typical regions.
What to check instead:
- ESS > 100 (or ESS/n > 0.05): Rules out extreme weight degeneracy
- TTC > 0.7: Confirms logger has good coverage of target actions
- CLE floor acceptable: Theoretical variance lower bound meets precision requirements
All three conditions must hold for reliable logs-only IPS.
6. Triply robust underperforms in this setting
tr-cpo-e achieves Top-1 = 32.9%, RMSE^d = 0.136 (worse than DR variants).
Why: Adding a third robustness layer (oracle label correction term) introduces complexity without benefit when:
- Oracle labels are abundant (25-100% coverage in many regimes)
- Overlap is poor (triple robustness doesn't fix lack of overlap)
- Careful tuning is required to avoid bias from the correction term
Recommendation: Use DR with cross-fitted Q̂ and SIMCal-W. Triple robustness adds marginal theoretical protection at substantial implementation complexity.
6.6 Methodological Takeaways
1. On-policy Direct Method should be your default
Use direct+cov when you can generate fresh responses on shared prompts:
- Best ranking accuracy (94.3% pairwise)
- Fast (2.9s)
- No propensity estimation, no overlap requirement
- Stable across oracle coverage levels
2. OPE requires overlap (and/or DR with solid outcome model)
Use IPS only when:
- Policies are very similar (e.g., small temperature/top-p changes)
- TTC > 0.7 (verified via diagnostic)
- ESS > 100 after SIMCal-W
- CLE floor meets precision requirements
Otherwise prefer DR with calibrated rewards and cross-fitted critics. Understanding it still trails DM and costs more compute.
3. Calibration and covariates are non-negotiable
- Calibration required for valid CIs (0% coverage without it)
- Calibration also improves ranking (+5-10 pp top-1 accuracy)
- Adding response_length covariate corrects systematic judge bias
- Future work: Systematically discover additional bias-correcting covariates (domain, difficulty, user context)
4. OUA inference is required for honest uncertainty
- Without OUA: 0% CI coverage
- With OUA: 85-95% coverage (honest uncertainty quantification)
- OUA share typically 30-50% at realistic oracle coverages
- Use delete-one-fold jackknife to estimate Var_cal
7. Practical Guidance and Diagnostics
Section 6 validated the theory. This section translates empirical findings into actionable recommendations for deploying CJE in production evaluation pipelines.
7.1 Default Recommendation: Direct Method + Two-Stage Calibration
Based on Arena evidence, the default recommendation for LLM evaluation is:
Use direct+cov (Direct Method with two-stage calibration)
Why this is the practical winner:
- Best ranking accuracy: 94.3% pairwise, 89.4% top-1, τ = 0.887
- Fast: 2.9s runtime (7× faster than calibrated-dr-cpo+cov)
- Simple deployment: No teacher forcing, no propensity estimation, no overlap requirement
- Robust: Stable performance across oracle coverage levels (5-100%)
- Valid inference: 87% CI coverage with OUA (vs 0% without calibration)
Requirements:
- Ability to generate fresh responses from each policy on a shared prompt set
- 200-500 oracle labels for calibration (depending on target precision)
- Representative prompt distribution (reflects deployment conditions)
# Generate fresh responses for each policy on shared prompts
# Label 25% with oracle (GPT-5, human raters, business metrics)
# Score all responses with cheap judge (GPT-4.1-nano, custom classifier)
results = analyze_dataset(
fresh_draws_dir="path/to/policy_responses",
include_response_length=True, # Two-stage calibration
verbose=True
)
# Results include policy value estimates with valid 95% CIs
7.2 When to Use Off-Policy Evaluation (IPS/DR)
Off-policy methods (IPS, DR) are for scenarios where you cannot generate fresh responses.
Valid use cases:
- Historical analysis: Evaluating past policies using logged production data
- Third-party model evaluation: Cannot regenerate responses from proprietary models (e.g., GPT-4 vs Claude)
- Expensive-to-run policies: Policies that are costly to execute (e.g., multi-agent systems with extensive tool use)
- Online learning: Using logged feedback to evaluate counterfactual policies without deployment
Pre-deployment checklist for OPE:
Before deploying logs-only IPS/DR, verify ALL of the following:
1. Overlap diagnostic (TTC > 0.7):
- TTC > 0.7: IPS viable (logger has good coverage of target actions)
- 0.3 ≤ TTC < 0.7: Use DR with outcome model (IPS alone will be unstable)
- TTC < 0.3: IPS doomed, use Direct Method or accept that evaluation requires fresh data
2. Effective sample size (ESS > 100):
After SIMCal-W stabilization, weights must not be degenerate
3. CLE floor meets precision requirements:
The Coverage-Limited Efficiency bound gives a theoretical floor on logs-only variance. If CLE floor is larger than your MDE (minimum detectable effect) requirement, logs-only IPS cannot achieve your precision target.
Recommended estimator by scenario:
| TTC | ESS/n | Recommended | Notes |
|---|---|---|---|
| > 0.7 | > 0.05 | calibrated-ips | Logs-only viable, use SIMCal-W |
| 0.3-0.7 | > 0.05 | calibrated-dr-cpo+cov | Need outcome model to stabilize |
| < 0.3 | Any | direct+cov | IPS/DR will fail, need fresh draws |
| Any | < 0.05 | direct+cov | Weight degeneracy too severe |
7.3 Diagnostics Checklist
Before trusting CJE estimates, validate the following assumptions and quality checks:
A. Calibration Quality
- ☐ Monotonicity check: R̂(s) is non-decreasing in s. Plot calibration curve E[Y | S=s] vs s. Violations indicate preference inversion.
- ☐ Residual analysis: No systematic patterns in (Y - R̂(S)). Plot residuals vs S, X, policy index. Systematic patterns indicate miscalibration.
- ☐ Mean preservation: |mean(Y) - mean(R̂(S))| < ε. Verify E[R̂] ≈ E[Y] on oracle sample.
B. Transportability (Assumption S2)
☐ Transportability test: Y ⊥ Sel | X, A, S
- Regress Y on {S, X, policy indicators} on oracle sample
- Test H₀: policy coefficients = 0 (Bonferroni-corrected)
- Rejection indicates judge bias varies by policy
- Mitigation: Include policy as covariate in two-stage calibration
Safety circuit breaker: The unhelpful policy in the Arena experiment demonstrates automatic adversarial detection via transportability failure. When a new policy fails transportability (p < 0.05), treat it as a stop signal requiring manual review before production deployment.
C. Off-Policy Diagnostics (if using IPS/DR)
- ☐ ESS check: ESS > 100 (or ESS/n > 0.05) after SIMCal-W. Low ESS indicates weight degeneracy
- ☐ TTC diagnostic: TTC > 0.7 for reliable IPS. Measures coverage of target-typical actions in logged data
- ☐ Weight concentration: Max(w) / Median(w) < 100, CV(w) < 2
- ☐ CLE floor acceptable: Theoretical variance floor < MDE²
D. Coverage Validation
- ☐ A/A test: Evaluate base policy against itself. Should detect no difference (p > 0.05). Run periodically to detect calibration drift.
- ☐ CI coverage check: On held-out oracle sample, verify 95% CIs contain true values ~95% of time
7.4 Common Pitfalls
Pitfall: "High judge-oracle correlation means calibration is optional"
❌ Wrong: "My judge has 0.85 correlation with oracle, so I can skip calibration"
✅ Correct: Even with high correlation, judge scores are on arbitrary scale. Arena evidence: naive-direct achieves τ = 0.817 but 0% CI coverage.
Mitigation: Always calibrate. It's cheap (200-500 oracle labels) and essential.
Pitfall: "ESS > 100 means my IPS estimate is reliable"
❌ Wrong: "I have ESS = 500 after SIMCal-W, so IPS is fine"
✅ Correct: High ESS means weights aren't degenerate, but doesn't guarantee coverage. Arena evidence: calibrated-ips has ESS = 90.2% but τ = −0.058 (near-random ranking). Root cause: TTC = 0.28 (low coverage).
Mitigation: Check TTC diagnostic. If TTC < 0.3, use Direct Method regardless of ESS.
Pitfall: "Calibration only needs to be done once"
❌ Wrong: "I calibrated my judge in January, it's good forever"
✅ Correct: User preferences drift over time, breaking judge-oracle alignment. Arena evidence: Claude sycophancy initially loved, later hated.
Mitigation: Run transportability test monthly on fresh oracle batches. Recalibrate when p < 0.05.
7.5 Covariate Strategy
Always include response_length in two-stage calibration
Arena evidence shows consistent ranking improvement across all estimators:
- direct: +5.3 pp top-1 accuracy
- calibrated-dr-cpo: +6.5 pp top-1 accuracy
Why response_length matters:
- Judges reward verbosity even when longer responses don't provide more value
- This is a side channel: model can increase S without increasing Y*
- Two-stage calibration blocks this channel by residualizing Y on length before isotonic calibration
results = analyze_dataset(
fresh_draws_dir="path/to/responses",
include_response_length=True, # Automatically adds length covariate
verbose=True
)
Other covariates to consider:
| Covariate | Bias Type | When to Include | Implementation |
|---|---|---|---|
| prompt_domain | Genre bias | Judge prefers certain topics | Categorical covariate |
| prompt_difficulty | Complexity bias | Judge favors simple/complex tasks | Continuous or ordinal |
| user_context | Demographic bias | Judge aligns with certain user types | Categorical (if ethical) |
| response_structure | Format bias | Judge prefers bullet lists, citations | Feature engineering |
| temporal | Time drift | Judge preferences change over time | Time index or bins |
Systematic covariate discovery:
- Inspect largest residuals: Sort oracle sample by |Y - R̂(S)| and manually review top 50 samples. Look for patterns: Do certain prompt types or response formats have systematic errors?
- Feature importance: Train gradient boosted tree to predict residuals (Y - R̂(S)) using candidate covariates. High-importance features are candidates for two-stage calibration.
- Segmented analysis: Split data by covariate levels, check if calibration curves differ. E.g., plot E[Y|S] vs S separately for short/medium/long responses. Different curves indicate covariate-dependent bias.
Important constraints:
- ✅ DO use covariates for calibration f(S,X): Corrects systematic judge bias
- ❌ DON'T use covariates for action reweighting: Changes target population
Example: Including response_length in f(S,X) removes length bias from judge scores. It does NOT reweight toward longer or shorter responses. The marginal distribution of lengths is unchanged.
7.6 Temporal Monitoring and Recalibration
The drift problem: Judge-oracle calibration can break over time as user preferences evolve.
Arena case study: Claude sycophancy
- Week 1: Users enjoyed validating responses ("You're absolutely right!")
- Week 4: Same users found sycophancy cloying and untrustworthy
- Result: Judge trained on Week 1 data would systematically overrate sycophantic responses in Week 4
- Outcome: Preference inversion (high S predicts low Y)
Detection strategy:
Run transportability test on fresh oracle batches monthly:
- Collect 200-500 fresh oracle labels on new prompts
- Apply existing calibration f_old to get R̂ = f_old(S, X)
- Test H₀: E[Y_new - R̂_new] = 0 (Bonferroni-corrected)
- If p < 0.05: Calibration has drifted
Mitigation options:
Option A: Recalibrate (fast)
Works for most drift
- • Update f: S → Y mapping using 200-500 fresh oracle labels
- • Doesn't require retraining judge
- • Works when judge rankings are still good but scale has shifted
Option B: Refine judge (slower)
Fixes systematic bias
- • Manually inspect top residuals: |Y_new - f_old(S,X)|
- • Identify systematic patterns (e.g., "judge consistently underrates concise responses")
- • Update judge prompt/template to fix bias
- • Produces better-aligned judge for future use
Production design pattern:
- Continuous oracle collection: 5-10% coverage on all production traffic
- Monthly transportability tests on recent batches
- If test fails (p < 0.05):
- a. Recalibrate f using last month's oracle labels
- b. If recalibration fails repeatedly: Refine judge
- A/A tests quarterly: Evaluate base policy vs itself
- Should detect no difference
- If p < 0.05: Calibration is biased
This creates a closed-loop monitoring system that detects and corrects calibration drift before it affects decisions.
7.7 Multi-Turn and Agent Evaluation
CJE extends naturally to multi-turn conversations and agent systems. Two patterns:
Pattern A: Terminal-Outcome Scoring
Score only the final output with judge S_T, calibrate to oracle Y_T:
fresh_draws_dir="agent_conversations/", # Each file = full conversation
score_field="terminal_score", # S_T from judge
oracle_field="terminal_outcome", # Y_T from oracle
include_response_length=True
)
Advantages:
- Minimal labeling cost (one label per conversation)
- Simple: reuses single-turn CJE machinery
- Natural for task-completion scenarios (coding, tool use, factual Q&A)
Pattern B: Step-Weighted Trajectory Rewards
Score each turn, calibrate step-wise, aggregate:
Where αt ∈ [0,1] are step weights:
- Uniform: αt = 1/T (all steps equal)
- Discounting: αt = γ(t-1) (earlier steps matter less)
- Milestone: αt ∈ {0, 1} (only score key decision points)
- Learned: Train α from oracle trajectory-level labels
T =
weights = [discount**t
R =
Important notes for multi-turn evaluation:
- Cluster by trajectory: Each conversation is a cluster, not each turn. Standard errors must account for within-trajectory correlation.
- OUA with trajectories: Recompute R_τ(-k) for each delete-one-fold calibrator
- Sequential IPS degenerates: Propensities multiply across steps (w_τ = Π π/π₀), degeneracy worsens exponentially. Prefer Direct Method or DR with trajectory-level critic for multi-turn (T > 3-5).
7.8 Integration with Existing Evaluation Pipelines
CJE can be integrated at three levels depending on your infrastructure maturity and resource constraints:
Level 1: Minimal Integration (Replace Judge Scores)
If you already have evaluation infrastructure that collects judge scores:
policy_values = aggregate(judge_scores) # Mean or ranking
calibrator.fit(judge_scores_oracle, oracle_labels)
policy_values_cje = aggregate(calibrated_rewards) # Now on Y-scale
Pros: Minimal code changes, immediate improvement in ranking accuracy. Limitations: No OUA inference (invalid CIs), no covariates, no diagnostics.
Level 2: Full Integration (CJE as Evaluation Backend)
Replace entire evaluation backend with CJE:
fresh_draws_dir=f"experiments/{experiment_id}/responses",
include_response_length=True,
estimator="direct+cov", # or auto-select
verbose=True
)
"policy_values": results.estimates,
"confidence_intervals": results.confidence_interval(alpha=0.05),
"winner": results.best_policy,
"diagnostics": {
"transportability_test": results.diagnostics.transportability_pvalue
}
})
Pros: Full CJE benefits (OUA, covariates, diagnostics, valid CIs). Limitations: Requires infrastructure for oracle labeling service.
Key integration points:
- Oracle labeling service: Budget 5-25% of evaluation samples. Sources: GPT-5, human raters, business metrics (conversion, retention). Storage: Append oracle labels to existing sample metadata.
- Judge scoring service: Keep existing cheap judge (GPT-4.1-nano, custom classifier). Add response_length feature extraction. Store judge scores alongside responses.
- Calibration service: Runs monthly or when transportability test fails. Input: Oracle sample (judge scores + oracle labels). Output: Calibration function f: (S, X) → R. Versioned and logged for reproducibility.
- Diagnostics dashboard: Transportability test p-value (monthly), A/A test results (quarterly), OUA variance share (per analysis), ESS/TTC (if using OPE), calibration curve visualization.
7.9 Extended Common Pitfalls
Pitfall: "OUA is only for small oracle samples"
❌ Wrong: "I have 50% oracle coverage, so I can skip OUA"
✅ Correct: OUA matters whenever you're learning a calibration function. At 25% coverage, OUA contributes ~30% of total variance. At 50% coverage, ~15-20%. Only at 100% coverage does OUA = 0 (no calibration needed).
Mitigation: Always use OUA unless oracle coverage = 100%.
Pitfall: "Covariates should go in propensity model for IPS"
❌ Wrong: "Include response_length in π(A|X) to improve overlap"
✅ Correct: Covariates go in calibration f(S,X), NOT propensity model. Including covariates in π(A|X) changes the target population. Including covariates in f(S,X) removes systematic judge bias.
Mitigation: Use two-stage calibration f(S,X) with response_length. Don't modify propensity model unless doing transportability adjustment.
Pitfall: "Teacher forcing gives accurate propensities"
❌ Wrong: "I can score any response under any policy with teacher forcing"
✅ Correct: Teacher forcing is numerically unstable for text generation. Arena evidence: Even `clone` (identical to `base`) has weight degeneracy. Small differences in tokenization, rounding, or sampling compound across sequence.
Mitigation: Use Direct Method when possible. If must use IPS, apply SIMCal-W and verify TTC > 0.7.
7.10 Quick Reference: Decision Tree
Oracle Budget Phases
- Phase 1 (Calibration): 50-100% coverage, n=500-1K
- Phase 2 (Optimization): 25% coverage, n=2-5K
- Phase 3 (Production): 10-25% coverage, n=5K+
Always Include
- ✅ AutoCal-R calibration (never skip this)
- ✅ OUA inference (delete-one-fold jackknife)
- ✅ response_length covariate (two-stage)
- ✅ Monthly transportability tests
- ✅ Quarterly A/A tests
Red Flags (Stop and Diagnose)
- 🚩 A/A test detects spurious difference (p < 0.05)
- 🚩 CI coverage < 80% on held-out oracle sample
- 🚩 Transportability test fails (p < 0.05)
- 🚩 ESS < 100 for IPS/DR
- 🚩 TTC < 0.3 for any off-policy method
8. Conclusion
8.1 The Payoff
Your AI metrics were lying to you. Not because the judges were bad, but because standard evaluation practices ignore three systematic failures:
- Uncalibrated judges → preference inversion: High judge scores can predict low oracle values
- Ignoring oracle uncertainty → invalid confidence intervals: 0% coverage makes CIs useless for decisions
- Standard IPS → catastrophic failure: Near-random ranking despite high ESS when coverage is low
CJE provides the statistical corrections that fix these failures:
✅ AutoCal-R calibration enforces monotonicity (S → R), eliminating preference inversion
- Arena evidence: Reduces RMSE^d by 73%, improves top-1 accuracy by 9.8 pp
- Required for valid inference: 0% → 87% CI coverage
✅ OUA inference accounts for calibration uncertainty via delete-one-fold jackknife
- Arena evidence: Restores honest uncertainty quantification
- Typical contribution: 30-50% of total variance at realistic oracle coverages
✅ CLE theory + TTC diagnostic identifies when logs-only IPS fails
- Arena evidence: TTC = 0.28 predicts IPS failure (τ = −0.058) despite ESS = 90%
- Decision rule: TTC < 0.3 → use Direct Method instead
The Result
Reliable policy evaluation at 14× cost reduction (GPT-4.1-nano judge + 25% GPT-5 oracle labels):
- ✓94.3% pairwise accuracy (direct+cov baseline)
- ✓Valid 95% confidence intervals (vs 0% without calibration)
- ✓Fast iteration (2.9s runtime, 7× faster than DR)
- ✓Production-ready (open-source implementation, reproducible experiments)
8.2 Implementation
The complete CJE framework is available as an open-source Python package:
results = analyze_dataset(data, oracle_col='Y', surrogate_col='S')
For Practitioners
- ✓ Oracle-efficient evaluation (10-25% coverage)
- ✓ Valid uncertainty quantification
- ✓ Diagnostic transparency
- ✓ Progressive refinement
- ✓ Temporal monitoring
For Organizations
- ✓ 14× cost reduction
- ✓ Faster iteration (<3s)
- ✓ Risk mitigation (valid CIs)
- ✓ Scalable infrastructure
8.3 The Broader Context: CJE Within the CIMO Framework
CJE solves the static evaluation problem (Pillar A):
Given policies {π₁, ..., π_K} and a quality definition Y*, estimate V(π) = E[Y(π)] with valid confidence intervals, using a cheap judge S and sparse oracle labels.
This is foundational for the broader CIMO Framework:
Pillar A: CJE (Static Evaluation) ← This document
- Layer 2: Programmable Judges + Calibration (AutoCal-R, SIMCal-W)
- Layer 3: Causal Judge Evaluation (Direct/IPS/DR estimators with OUA inference)
- Layer 6: CLOVER (Continuous judge improvement via selective inference)
Status: ✅ Valid: Production-ready with open-source implementation
Pillar B: CCC (Dynamic Calibration)
- Continuous Causal Calibration under drift
- Causal Nyquist Rate: f_exp > 2 × ν_bias
- Fuses biased surrogates with sparse experiments
Status: 🔬 Experimental: Active research, theoretical framework established
Pillar C: Y*-Aligned Systems
- Layer 1: Y* (Idealized Deliberation Oracle)
- Layer 4: Y*-Alignment via SDPs (Surrogate Design Principles)
- Layer 5: Net IDO Impact (honest impact accounting)
- Layer 0: Bridge Validation Protocol (testing A0: E[Y*|X,A] = E[Y|X,A])
Status: 🔬 Experimental + 📐 Theory: Framework defined, empirical validation in progress
The stack dependency:
- CCC builds on CJE: Assumes you can calibrate at each time point (Layer 3) → extends to temporal fusion
- Y*-Alignment builds on CJE: Optimization requires evaluation (Layer 3) → connects optimization to welfare via SDPs (Layer 4)
- All three require Bridge Assumption (A0): Y aligns with Y* → validated via PTE and construct audits (Layer 0)
CJE is the empirical foundation. Get this right, or everything above it fails.
8.4 Limitations and Future Work
What CJE provides:
- ✅ Valid estimates of V(π) = E[Y(π)] with honest uncertainty
- ✅ Diagnostic tests for assumptions (transportability, oracle MAR)
- ✅ Guidance on when methods fail (TTC, ESS, CLE bounds)
What CJE does NOT solve:
❌ Quality definition (Y vs Y*)
CJE assumes Y is given and aligned with what you care about (Y*). If Y is a bad proxy for welfare, CJE will give you precise estimates of the wrong thing.
Addressed by: Bridge Validation Protocol (Layer 0) via PTE and construct validity audits. See the Y*-Aligned Systems framework for full treatment.
❌ Temporal drift
CJE provides transportability tests and recalibration strategies, but doesn't automatically adapt.
Addressed by: CCC (Pillar B) extends CJE to handle drift via continuous calibration. Requires explicit monitoring (monthly tests, recalibration when p < 0.05).
❌ Optimization safety
CJE evaluates fixed policies, doesn't prevent Goodhart's Law during optimization. If you optimize against calibrated judge R̂, side channels can still be exploited.
Addressed by: Y*-Alignment (Layer 4) via Surrogate Design Principles. See safe optimization framework.
Open research questions:
- Human oracle validation: Arena uses GPT-5 as oracle. How do results change with human preference labels (crowdsourced, expert annotations), business metrics (conversion, retention, revenue), and multi-rater disagreement modeling?
- Minimum viable oracle coverage: Can we push below 5% with active learning for label allocation, transfer learning from related domains, and more sophisticated calibration methods (deep calibration, conformal prediction)?
- Covariate discovery: Systematic identification of bias-correcting covariates beyond response_length:prompt domain, difficulty, user context, response structure (citations, formatting), automated feature engineering from residuals.
- Multi-objective evaluation: Extending CJE to vector-valued outcomes: helpfulness, harmlessness, honesty simultaneously. Pareto frontier estimation with valid CIs, scalarization strategies that preserve alignment.
- Transportability across domains: Using DR for domain adaptation from source domain (expert raters) to target domain (general users) with density ratio estimation and robustness.
8.5 Next Steps for Practitioners
If you're evaluating LLM systems today:
- Start with direct+cov: Generate fresh responses on shared prompts, use 25% oracle coverage. This gets you 99% ranking accuracy with valid CIs. Fastest path to reliable evaluation.
- Run diagnostics: Check transportability, oracle MAR, A/A tests. Validates assumptions before trusting estimates, identifies problems early.
- Monitor temporally: Monthly transportability tests, quarterly A/A tests. Detects calibration drift before it affects decisions. Recalibrate when p < 0.05.
- Optimize oracle budget: Use OUA share diagnostic to determine bottleneck. OUA share > 50%: add more oracle labels. OUA share < 20%: add more prompts. Sweet spot: 10-25% oracle coverage for production.
- Integrate incrementally: Start with minimal integration (replace judge scores with R̂), expand to full CJE backend. Lower barrier to adoption, validates benefits before full commitment.
If you're building evaluation infrastructure:
- Design for calibration: Oracle labeling service + calibration service as first-class components. Budget 10-25% of samples for oracle labels, version calibration functions for reproducibility.
- Automate diagnostics: Dashboard with transportability tests, A/A tests, OUA share, ESS/TTC. Continuous monitoring (not one-time checks), alerts when assumptions fail.
- Plan for recalibration: Monthly refresh cycle for calibration function. User preferences drift, judges need updating. Closed-loop system maintains alignment.
- Support multi-turn: Terminal-outcome pattern as default, step-weighted for process evaluation. Most use cases work with single terminal score, flexibility for complex agent systems.
If you're doing research on LLM evaluation:
- Validate with human oracles: Replicate Arena results with human preference labels and business metrics. Most critical open question. Establishes external validity.
- Push oracle coverage lower: Active learning, transfer learning, deep calibration. Every percentage point reduction in oracle budget = cost savings at scale. Current floor: ~5% coverage.
- Discover bias-correcting covariates: Systematic feature engineering for two-stage calibration. response_length is just the beginning. Potential for 5-10 pp ranking improvement per covariate.
- Extend to vector outcomes: Multi-objective evaluation with valid CIs. Real systems optimize for multiple attributes. Need Pareto frontier estimation, not just scalar V(π).
Final Thought
The difference between measuring and measuring well is the difference between deployment confidence and deployment recklessness.
Standard evaluation practices (uncalibrated judges, ignored oracle uncertainty, blind trust in ESS) produce metrics that lie. These lies are systematic, predictable, and fixable.
CJE provides the fixes: calibration via Design-by-Projection, OUA inference for honest uncertainty, CLE theory for knowing when to give up on logs-only estimation.
The Arena benchmark validates the theory: 99% ranking accuracy at 14× cost reduction, with valid confidence intervals that enable confident decisions.
The infrastructure is ready: open-source implementation, diagnostic tests, integration patterns, temporal monitoring.
Measure well. Decide confidently. Ship safely.
For complete technical details, mathematical proofs, and comprehensive appendices covering all assumptions, diagnostics, and theoretical results, see the full technical report at github.com/cimo-labs/cje.