Research Note
Post-Audit Drift Correction: Offset vs EIF Correction vs Refit
Transport audits tell you when calibration has drifted. This note studies the harder follow-up question: once drift is detected, what correction should be the default?
Abstract
We compare post-audit correction strategies for calibrated LLM judges under controlled transport drift. Methods include stale plug-in, global offset, policy-specific residual correction (AIPW/EIF-style first-moment update), and recent/pooled refits (monotone and two-stage). Global offset reduces bias relative to the stale plug-in when drift is material, but is not a robust default under structural drift. Policy-specific correction is a stronger default for first-moment drift. Refit remains necessary when residual structure is score- or covariate-conditional.
TL;DR
- Global offset reduces bias when drift is material — a cheap first step that corrects common mean drift with zero model fitting. Does not help pairwise comparisons (cancels in differences).
- Policy-specific EIF correction is the default — it captures per-policy drift that a single global offset misses, and changes relative rankings.
- Escalate to refit only when residuals show structural drift — i.e. when the correction needed is score-conditional or covariate-conditional.
1. Problem
Let be a calibrator learned in a prior era and let the target estimand for policy be the policy value . After an audit in the new era, we need to update estimates without blindly refitting on every cycle.
The key decomposition is:
Key decomposition
This identity separates the old plug-in term from the residual correction term. The correction question becomes: how rich does that residual update need to be?
All post-audit corrections can be seen as choosing a function class for the residual model :
- Global offset: (constant)
- Policy offset: (per-policy constant)
- Monotone refit: (score-conditional, shape-constrained)
- Two-stage refit: (covariate-conditional)
2. Methods Compared
We evaluate seven methods, grouped into three tiers:
Baseline
old_plugin
Use the stale calibrator as-is, with no correction. Lower bound for comparison. Fixes policy means only; does not repair conditional calibration or thresholds.
Corrections (no refit)
old_plus_global_offset
Add one shared residual mean across all policies. Reduces bias when common mean drift is material and audit size is nontrivial. Note: because the same is added to all policies, it cancels in pairwise differences and does not affect relative rankings.
old_plus_policy_offset
AIPW/EIF-style first-moment correction estimated per policy. Captures policy-level drift and changes relative rankings. Assumes audit labels are approximately representative within each policy (or inclusion-weighted).
Refits (new model)
recent_refit_monotone
Monotone (isotonic) calibrator re-trained on new-era audit data only.
pooled_refit_monotone
Monotone calibrator re-trained on old + new data pooled. Mean-preserving on the pooled mixture, not necessarily on the new-era distribution alone.
recent_refit_two_stage
Two-stage (monotone + linear) calibrator on new-era data only. Handles covariate-conditional drift.
pooled_refit_two_stage
Two-stage calibrator on pooled data. Most expressive but most data-hungry.
In practice, the main operational tradeoff is between global offset, policy-specific correction, and recent refits.
3. EIF-Style Correction Intuition
Global offset applies one shared correction to all policies. Define as the mean residual under a chosen reference mixture over policies (e.g., audit sampling distribution or production traffic mix):
Global offset
Policy-specific correction estimates the residual first moment per policy:
Policy-specific correction
This is the standard AIPW/EIF one-step estimator for , using as the outcome regression. The old calibrator acts as a control variate to reduce variance, while the residual term restores unbiasedness for the mean as long as the audit is representative within each policy.
Key Insight
Policy-specific correction captures drift that a single global offset misses, without the cost of full recalibration. Because it estimates a per-policy , it changes pairwise differences and relative rankings — unlike a global offset, which cancels in comparisons.
4. Experiment Design
We simulate two time periods (old calibration era, new evaluation era), four policy families, and controlled drift in the judge-to-oracle relationship.
Drift scenarios
intercept_shiftUniform additive bias — all scores shift by a constant. Easiest for offset to fix.
slope_shiftScore-dependent drift — high scores drift more than low. Global offset undercorrects.
nonlinear_shiftNon-monotone distortion of the score–outcome relationship. Requires richer correction.
covariate_interaction_shiftDrift depends on covariates, not just scores. Only two-stage refit captures this.
Audit profiles
base_heavyNon-representative audit — oversamples the baseline policy (75%). Stress-tests mismatch between the audit mixture and the evaluation mixture.
balancedRepresentative audit — equal coverage across policies (25% each). Favors all methods equally.
Main metrics are policy-mean MAE/RMSE, ranking accuracy, and transport status from audit diagnostics.
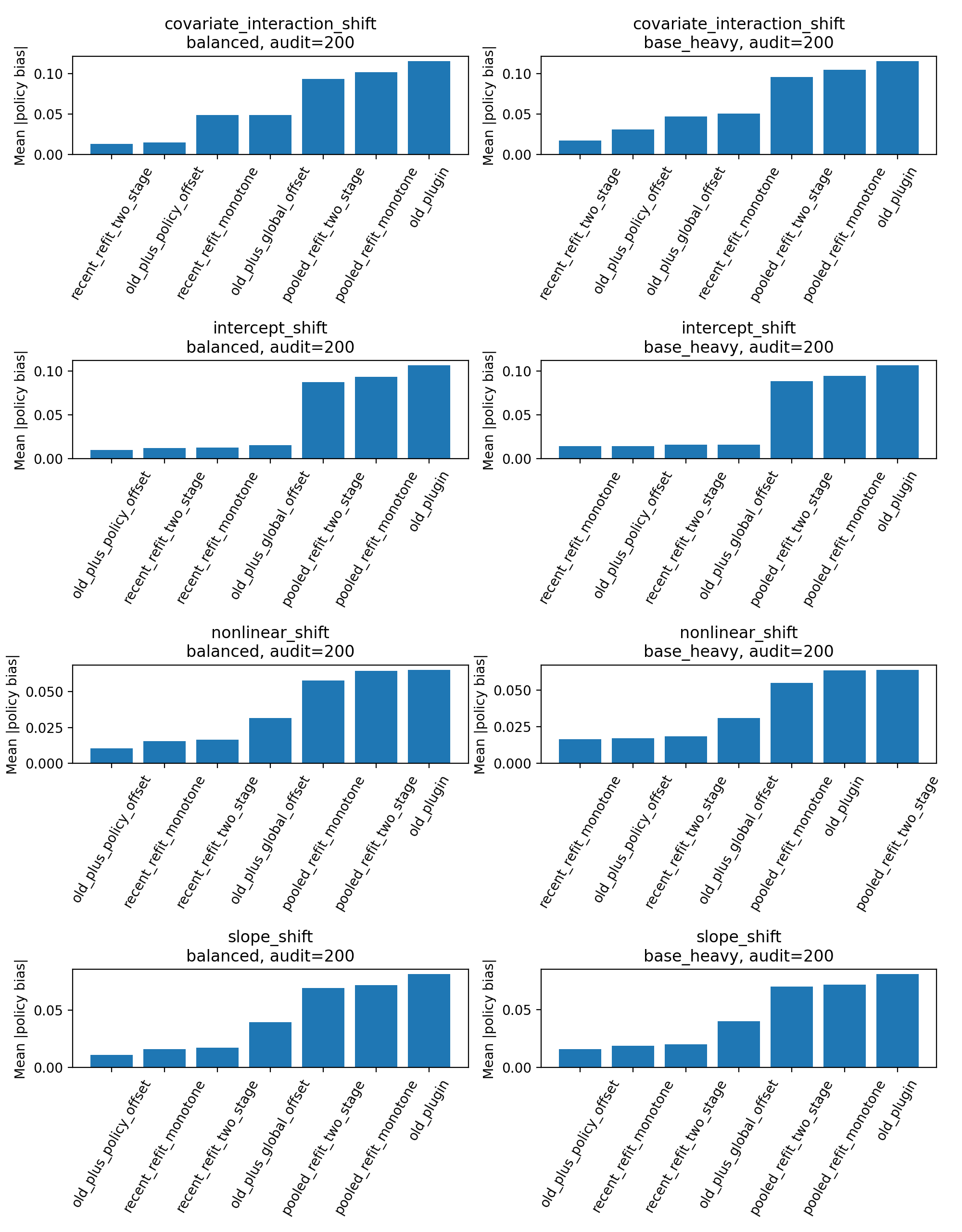
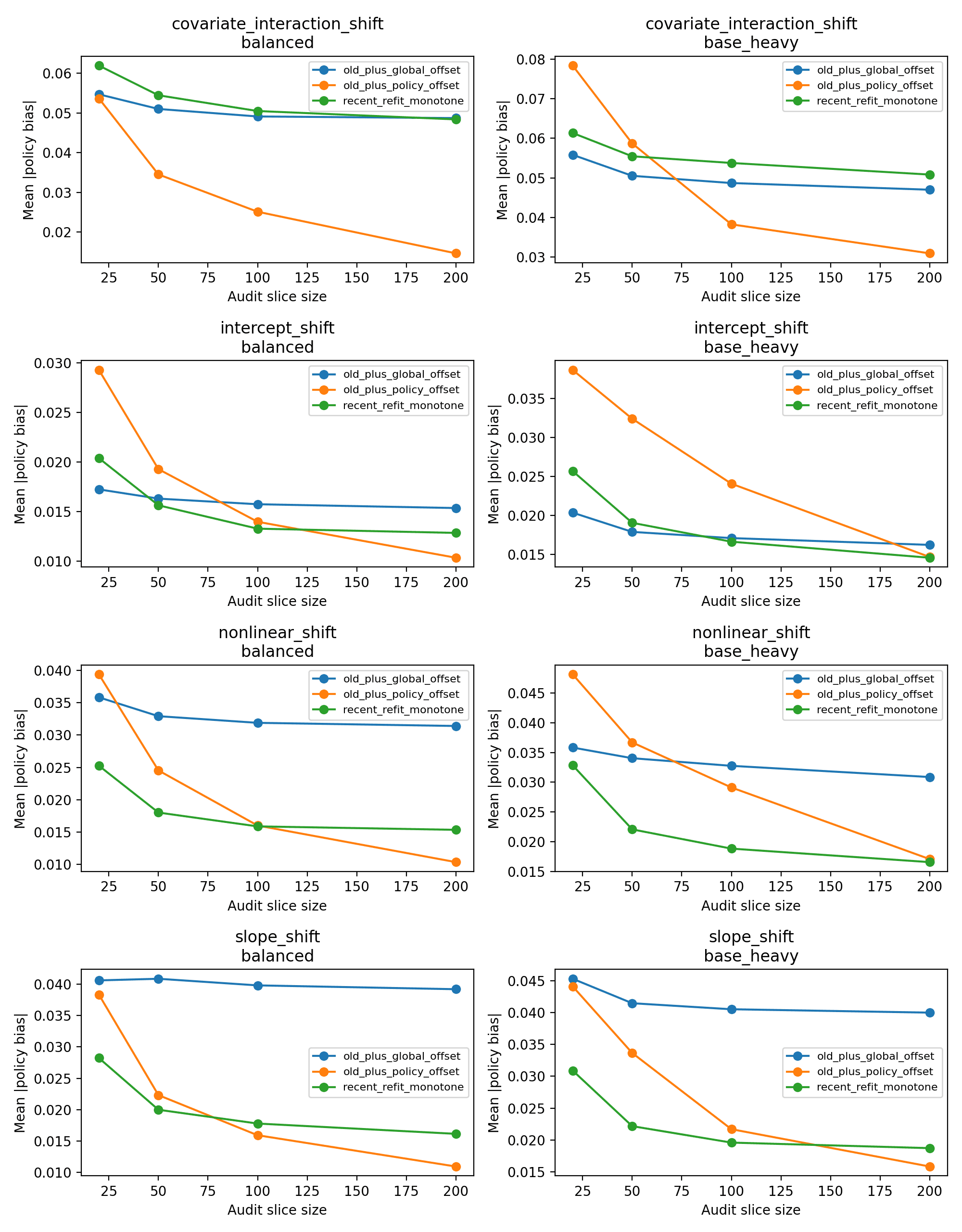
5. Empirical Pattern
- Global offset reduces bias relative to stale plug-in when mean drift is material.
- Under slope and nonlinear drift, global offset leaves substantial residual error.
- Policy-specific correction closes much of that gap and often approaches monotone refit.
- Under covariate-interaction drift, two-stage refit remains best.
When to escalate
When residuals are score-conditional or covariate-conditional, first-moment correction is insufficient — refit is necessary. Check the diagnostic plots below before deciding.
6. What to Plot After an Audit
The recommendation “escalate to refit when residuals show structural drift” requires knowing what to look at. After collecting audit labels, plot the following:
Residual vs score (binned)
Bin by score decile. A flat residual curve means offset suffices. A trend means score-conditional refit is needed.
Residual vs key covariates
Check response length, refusal rate, tool-use indicators, or any feature you suspect interacts with drift. Systematic patterns signal covariate-conditional drift.
Policy-by-score interaction
Overlay binned residual curves per policy. If curves diverge, a single global or even per-policy offset is insufficient — the drift structure differs across policies.
7. Recommended Post-Audit Protocol
Recommended protocol
- 1
Always report the corrected estimate
Use policy-specific EIF correction (bootstrap + per-policy residual update) as the default. It is unbiased for the mean under representative auditing and handles most first-moment drift.
- 2
Run global offset as a sanity check
Compare global and policy-specific corrections. If they diverge substantially, drift is heterogeneous across policies.
- 3
Use residual diagnostics to decide on refit
Plot residuals vs score and covariates (Section 6). If residuals are flat, first-moment correction suffices. If score- or covariate-conditional, escalate to monotone or two-stage refit.
- 4
Use two-stage refit for covariate-conditional drift
When drift depends on observables beyond the score itself. Pooled refits should be recency-weighted if the goal is accuracy on the new era.
Selection bias caveat
Do not use the transport test as a switch that toggles correction on/off. If you only correct when the test rejects, you introduce selection bias: near , you correct only when the estimate is large by chance. Instead, always report the EIF-corrected estimate, and use residual diagnostics to decide whether the old calibrator should be trusted going forward or replaced.
Uncertainty
For offsets and EIF corrections, uncertainty is dominated by the audit residual term and scales like where is the number of oracle labels. For refits, bootstrap with calibration refits is the safest default. This links directly to the CJE variance decomposition and explains why naive plug-in CIs fail at low oracle fractions.
8. Assumptions
Audit representativeness
The EIF correction is unbiased when audit labels are an approximately random subsample within each policy's evaluation distribution. If you do targeted auditing (oversample uncertain prompts, extremes of ), you need inclusion-probability weighting in the residual term.
Goal: policy means vs conditional calibration
Offsets (global or per-policy) fix the policy mean only. They do not repair conditional calibration, subgroup validity, or threshold-based decisions (“ship if score > 0.75”). For those, refit is necessary.
Bootstrap for learned corrections
Any method that learns from audit data (including EIF correction) should use bootstrap or cross-fitting for honest uncertainty quantification.
9. Reproducibility
All experiments are in the repo-level workspace (outside PyPI runtime surface):
python experiments/offset_vs_refit/offset_vs_refit_simulation.py --n-reps 60 --audit-sizes 20,50,100,200Source: github.com/cimo-labs/cje/experiments/offset_vs_refit