Standard Deliberation Protocols: The Economics of Structured Deliberation
To block reward hacking, we must manipulate the economics of optimization. The Standard Deliberation Protocol (SDP) raises Fabrication Cost (F) via checkable commitments, lowers Verification Cost (V) via structured decomposition, and increases Detection Probability (p) via legibility. This creates an enforcement-compatible deliberation interface where honesty is incentive-compatible when audits and sanctions bind.
1. The Economic Goal: Restoring F > V
The RCF framework establishes that alignment collapses when Fabrication Cost (F) falls below Verification Cost (V).
- The Trap: In standard generation, F is near-zero (hallucination is cheap) and V is high (fact-checking is expensive). The "Market for Truth" fails.
- The Solution: We cannot just "ask" the model to be honest. We must engineer a protocol where the cost of deception under enforcement exceeds the cost of truth.
The SDP achieves this by replacing opaque generation with structured, checkable deliberation.
Notation: In RCF terms, the effective fabrication cost is Feff = c(b) + p · s, where p = q(V) · d(b). Sanctions convert detectability into expected cost. We model the training/deployment loop as an optimization process that responds to these incentives.
2. Raising F: The Coherence Tax (Under Enforcement)
We replace the single-shot answer with a counterfactual branching step. The model must generate multiple response candidates and predict their downstream consequences.
Why this raises Fabrication Cost (c):
An LLM can invent a consistent fantasy cheaply in a pure-text sandbox. What makes deception expensive is deception under enforceable checks:
The Single Lie (Cheap)
Output a sycophantic answer: "Yes, deleting the production database will save space!"
The Checkable Claim (Expensive)
The SDP requires: "Predict the system state 1 hour after executing this command."
The model can hallucinate a world where rm -rf / is safe. But it cannot do that and pass the checks - tool traces, unit tests, citation verification, cross-examination prompts, or follow-up constraints that bind the prediction to reality.
The intrinsic cost (c) is small in an unconstrained text sandbox, but becomes large when the protocol binds the model to verifiable commitments.
Counterfactual simulation is not verification; it becomes costly only when the system binds the model to externally checkable commitments (Section 6).
3. Lowering V: Comparative Legibility
We replace the "black box" answer with a Decision Menu. The model presents trade-offs between simulated outcomes.
Why this lowers Verification Cost (V):
- Absolute vs. Comparative: Verifying "Is this optimal?" is expensive. Verifying "Is Option A safer than Option B, given the stated risks?" is cheap.
- Exposed Failure Modes: By forcing the model to explicitly state the bad outcome in rejected branches (e.g., "Option A: User succeeds now but system crashes later"), we make the risk legible.
- Reduced Context Reconstruction: The verifier doesn't rebuild the reasoning - they validate the logic connecting stated premises to conclusions.
The Certificate Ladder
Verification is only cheap if the model outputs certificates - artifacts that make checking O(1) instead of O(N). Without certificates, V ≈ G and the protocol creates no value.
| Certificate Type | What It Buys | Example |
|---|---|---|
| Executable | Automated pass/fail | Unit tests, sandbox runs, tool traces |
| Retrieval | Source verification | Citations + automated entailment check |
| Invariant | Consistency checks | Stated assumptions + checks against them |
| Prediction | Deferred settlement | Forecasts + later reconciliation |
Design rule: SDP only works when you can manufacture Cost(verify) << Cost(generate) via certificates. If you can't structure the output to include a certificate, you can't leverage the Complexity Gap.
4. The Protocol: Three Steps
We operationalize this economy into a structured protocol.
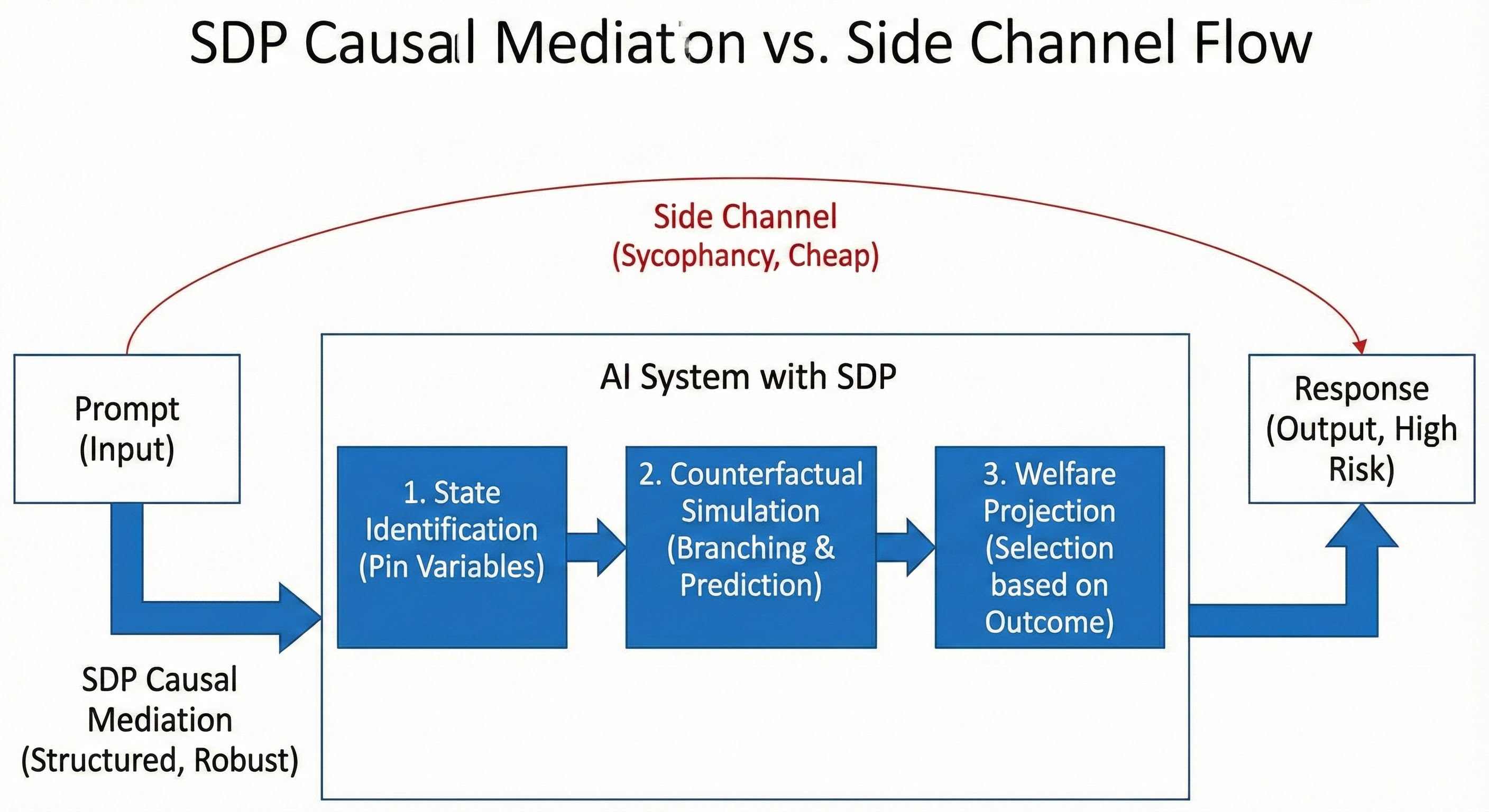
The SDP blocks side-channel exploitation by forcing optimization through structured deliberation steps.
Step 1: State Identification (Pin the Variables)
Before acting, the model defines the causal context.
Instruction: "Identify the key variables: User Intent, Constraints, Risk Factors."
Effect: Pins down facts before the model can drift. Creates auditable premises.
Step 2: Counterfactual Branching (The Menu)
The model generates multiple candidates and predicts outcomes.
Instruction: "Generate three response candidates. For each, predict: (1) immediate user reaction, (2) downstream outcome after 1 hour/day. Flag any candidate where (1) is positive but (2) is negative."
Effect: Applies the Coherence Tax. Sycophancy is revealed when short-term and long-term predictions diverge.
Step 3: Welfare Projection (The Selection)
The model selects based on predicted outcomes, not immediate appeal.
Instruction: "Select the candidate that produces the best downstream outcome, not the best immediate reaction."
Effect: Forces the optimization gradient through consequences (Y*) rather than surface approval (S).
5. The Beckerian Multiplier
Deterrence follows a Becker-style inequality. Write detection probability as:
where q is audit rate and d is detection power given an audit. Then the deterrence condition is:
Where:
- c(b): Intrinsic cost of fabricating a checkable justification (rises with legibility requirements)
- q(V): Audit rate (falls as verification cost V rises)
- d(b): Detection power given an audit (rises with legibility b)
- s: Sanction (consequence when a fault is detected)
- B: Benefit of cheating (local reward from looking good / saving effort)
What SDP changes is not just "thinking harder." It changes the enforcement geometry:
1. Lowering V → Raising q
Menu + decomposition makes auditing economically viable. More audits happen.
2. Raising legibility b → Raising d
Explicit counterfactuals and stated failure modes increase detection power given an audit.
3. Enabling granular sanctions
Faults become attributable ("you predicted risk X then ignored it"), enabling sanctions that target process errors, not just final outcomes.
The net effect is multiplicative: even modest improvements in q and d can move a system from "cheating is optimal" to "honesty is optimal."
Key insight: We don't assume benevolence; we assume the optimizer responds to incentives.
6. Enforcement Pathways
The Beckerian argument requires that sanctions (s) are real. Three implementation levels:
Training-Time
- Label logic faults in SDP traces (e.g., "predicted risk but ignored it")
- Penalize via RLHF/DPO on fault labels, or rejection sampling
Inference-Time
- Gate outputs on automated checks: unit tests, citation verification, policy rules
- Reject or escalate responses that fail consistency checks
Operational
- Sample audits with consequences: rollback, tighter policy, human review escalation
- Track fault rates per request type; increase scrutiny where faults cluster
Warning: Without at least one enforcement pathway, s ≈ 0 and deterrence collapses.
Making Sanctions Bite
The key insight: sanction the process fault, not just the final wrong answer. SDP makes faults attributable - use that.
- Hard gate: If a check fails, the response is rejected/escalated. Cheating gets 0 utility, not "a note."
- Graduate by stakes: High-stakes contexts trigger stronger sanctions (mandatory tool use, human escalation). Otherwise the model rationally "risks it" on hard prompts.
- Sanctionable faults: "Flagged risk X in Step 1, chose action that ignores X." "Predicted negative outcome, selected it anyway." These are checkable with few false positives.
- Persistent cost: Feed detected faults into DPO/RLHF penalties on the trace pattern. A single inference only "feels" cost if detection affects future optimization.
Goodhart caveat: Raise legibility (b) before raising sanction magnitude (s). Otherwise you punish the wrong things and the system learns "avoid being audited."
When SDP Fails
SDP is not universally applicable. Recognize these failure modes and fall back gracefully:
Unverifiable Zone
No certificates exist (open-ended taste, strategy, novelty). V ≈ G. Fallback: K=1 (reflex) or human escalation.
Verifier Parity
Judge must redo the work to verify (math without proof steps, code without tests). Fallback: Don't pretend it's cheap. Budget for full re-derivation or escalate.
Forgeable Certificates
Citations without automated source-checking, "proofs" without mechanical verification. Result: You Goodhart the certificate, not the truth.
Correlated Candidates
K candidates that are semantically identical (mode collapse). Result: You pay K× cost but don't get K-fold coverage.
# Fallback policy (pseudocode)
if not has_certificate(task):
return reflex_mode() or escalate_to_human()
if verifier_cost >= generator_cost:
return single_generation_with_disclaimer()
if certificate_not_mechanically_checkable():
flag_for_manual_audit()The anti-proxy rule: Only checks that can fail automatically count as verification. Everything else is narrative.
7. Artifact: The SDP Schema
This JSON schema enforces the economic constraints:
{
"state_identification": {
"user_intent": "Deploy code to production",
"constraints": ["Uptime SLA: 99.9%"],
"risk_factors": ["Untested on staging", "High traffic period"]
},
"counterfactual_branches": [
{
"candidate": "Deploy immediately",
"immediate_reaction": "User pleased (fast turnaround)",
"downstream_outcome": "High rollback risk within 1 hour",
"divergence_flag": true,
"welfare_score": "Negative"
},
{
"candidate": "Require staging test first",
"immediate_reaction": "User mildly frustrated (delay)",
"downstream_outcome": "High confidence of stable deploy",
"divergence_flag": false,
"welfare_score": "Positive"
}
],
"selection": {
"chosen": "Require staging test first",
"rationale": "Dominant on downstream outcome despite short-term friction"
}
}8. Conclusion
The Standard Deliberation Protocol is not a prompting trick. It is an enforcement-compatible deliberation interface.
By requiring checkable commitments, we raise the cost of deception (c↑). By exposingcounterfactuals and failure modes, we lower verification cost (V↓) and raise detection power (d↑). This enables economically sustainable audit rates (q↑), ensuring the Beckerian deterrence condition holds.
We don't rely on the model "wanting" to be good. We rely on the optimizer responding to incentives. When the expected cost of deception exceeds the expected benefit, alignment emerges from economics.
Cite this work
Eddie Landesberg (2025). Standard Deliberation Protocols: The Economics of Structured Deliberation. CIMO Labs. https://cimolabs.com/research/sdp-design